YGHTML V0.1.1버전에 다음의 기능을 추가하거나 개선하였습니다.
- HTML DOM Tree 생성 기능 추가
- DOM Tree Viewer 추가
- 주석 파싱 오류 제거
- 약간의 리펙토링(-_-;)
보고된 문제점
- Style Tag 처리불가
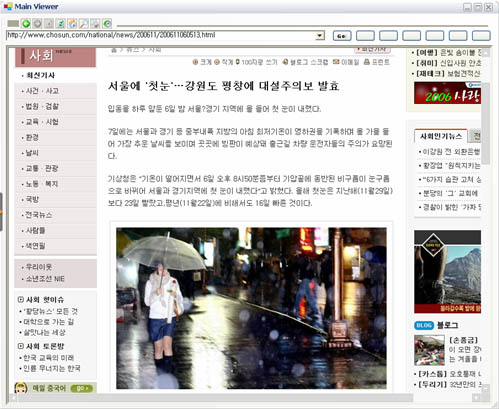
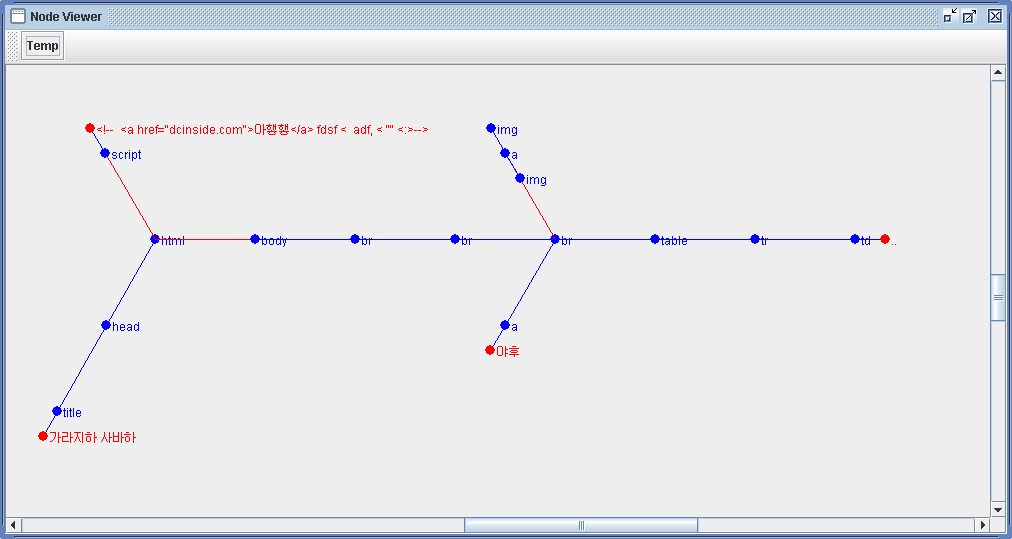
아래는 Sample 소스를 이용하여, DOM Tree를 생성, Viewer로 출력된 이미지 입니다.
파싱대상 소스(test.html)
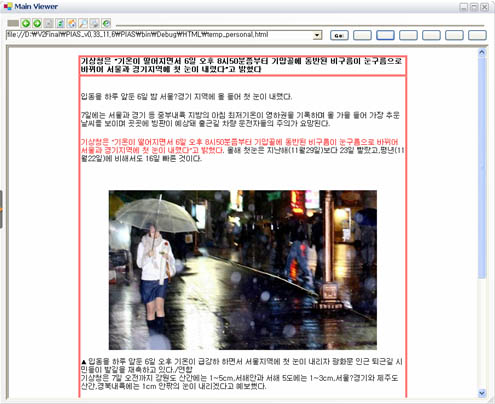
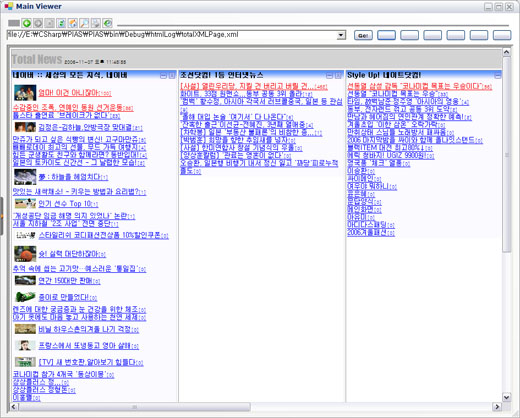
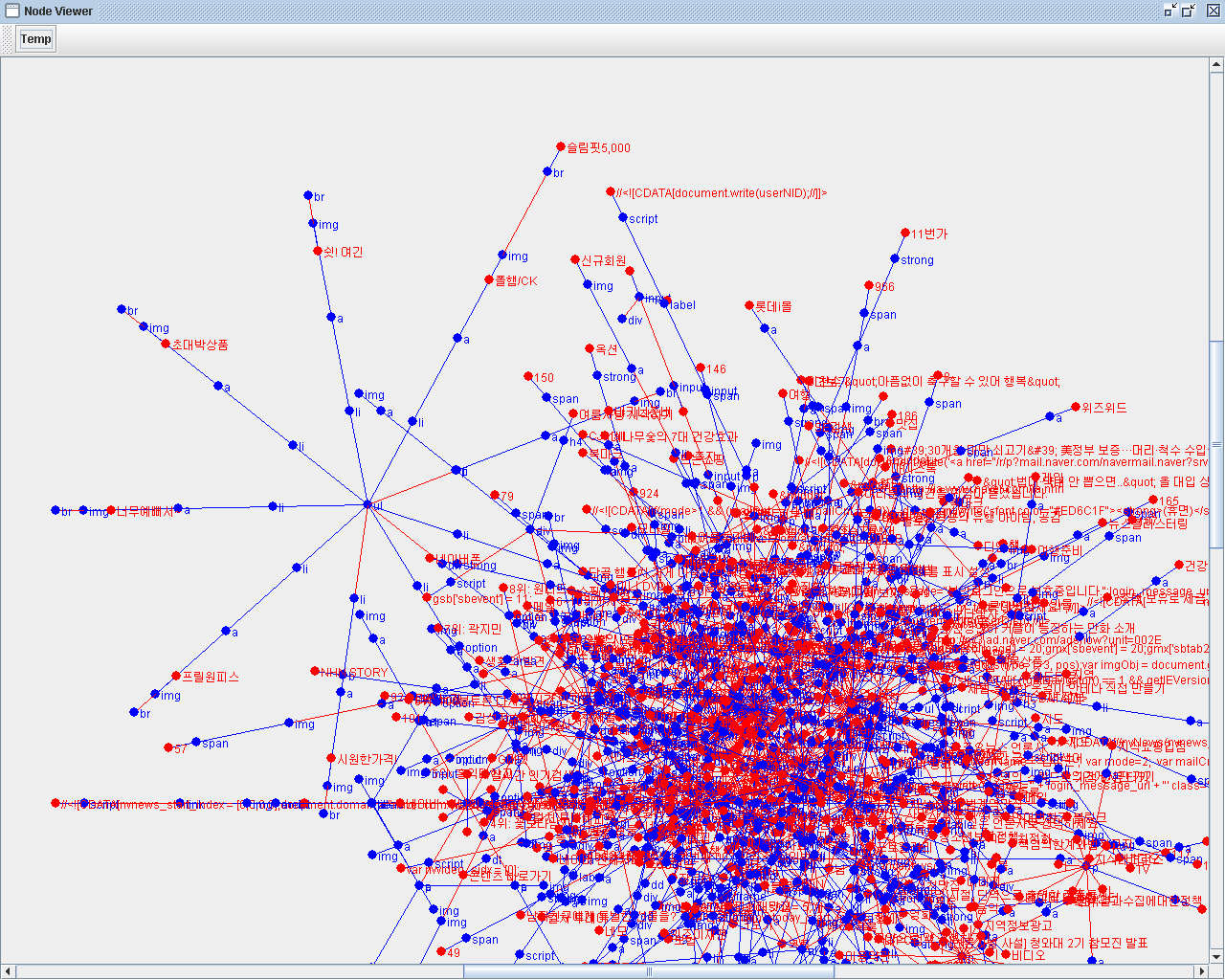
아래는 Naver 메인화면 소스를 적용해 본 이미지 입니다. (역시 복잡합니다.)
해당 소스파일 다운로드 ( Eclipse Project )
정확한 요구사항 분석도 없이,
설계에 대한 개념도 없이 HTML Parser가 절실한 상황에서 급조된 코드입니다..
분명히 저같이 Parser가 절실한 사람이 있다고 생각되기에, 저질 코드라도 용감, 무식하게 공개합니다..
소스의 질적인 부분에 대한 지적은 할말 없습니다..
또한 제가 파서에 대한 개념이 많이 부족한 상태라,
해당소스에서 더 괜찮은 아이디어나 제안이 있으시다면 언제든지 리플 부탁해요..
- HTML DOM Tree 생성 기능 추가
- DOM Tree Viewer 추가
- 주석 파싱 오류 제거
- 약간의 리펙토링(-_-;)
보고된 문제점
- Style Tag 처리불가
아래는 Sample 소스를 이용하여, DOM Tree를 생성, Viewer로 출력된 이미지 입니다.
파싱대상 소스(test.html)
<!document html> <html> <head> <title>가라지하 사바하</title> </head> <script> <!-- <a href="dcinside.com">아햏햏</a> fdsf < adf, < "" <:> --> </script> <body bgcolor=red background="img/bg.jpg"> <br> <br> <br> <a href="http://kr.yahoo.com">야후</a> <a href="kkk"><img src="yahoo.jpg"></img><img src="yahoo.jpg"/></a> <table bgcolor=lightgrey width=95%> <tr><td>..</td></tr> </table> <!-- 비정규 파싱 --> </body> </html> |
아래는 Naver 메인화면 소스를 적용해 본 이미지 입니다. (역시 복잡합니다.)
해당 소스파일 다운로드 ( Eclipse Project )
 invalid-file
invalid-file정확한 요구사항 분석도 없이,
설계에 대한 개념도 없이 HTML Parser가 절실한 상황에서 급조된 코드입니다..
분명히 저같이 Parser가 절실한 사람이 있다고 생각되기에, 저질 코드라도 용감, 무식하게 공개합니다..
소스의 질적인 부분에 대한 지적은 할말 없습니다..
또한 제가 파서에 대한 개념이 많이 부족한 상태라,
해당소스에서 더 괜찮은 아이디어나 제안이 있으시다면 언제든지 리플 부탁해요..
- 김영곤 (gonni21c@gmail.com)
'Expired > YG Html Parser' 카테고리의 다른 글
| Java Html Parser 개발시 유의사항 정리 (0) | 2010.08.20 |
|---|---|
| [Parser개발] 자바의 고성능 문자열 처리 : Rope (0) | 2009.09.12 |
| [자작] Java HTML Parser : YGHtml Parser V0.3.3 (5) | 2008.08.07 |
| Java기반 HTML 파서(Parser) : YGHTML Parser 0.1.1 (1) | 2008.06.01 |