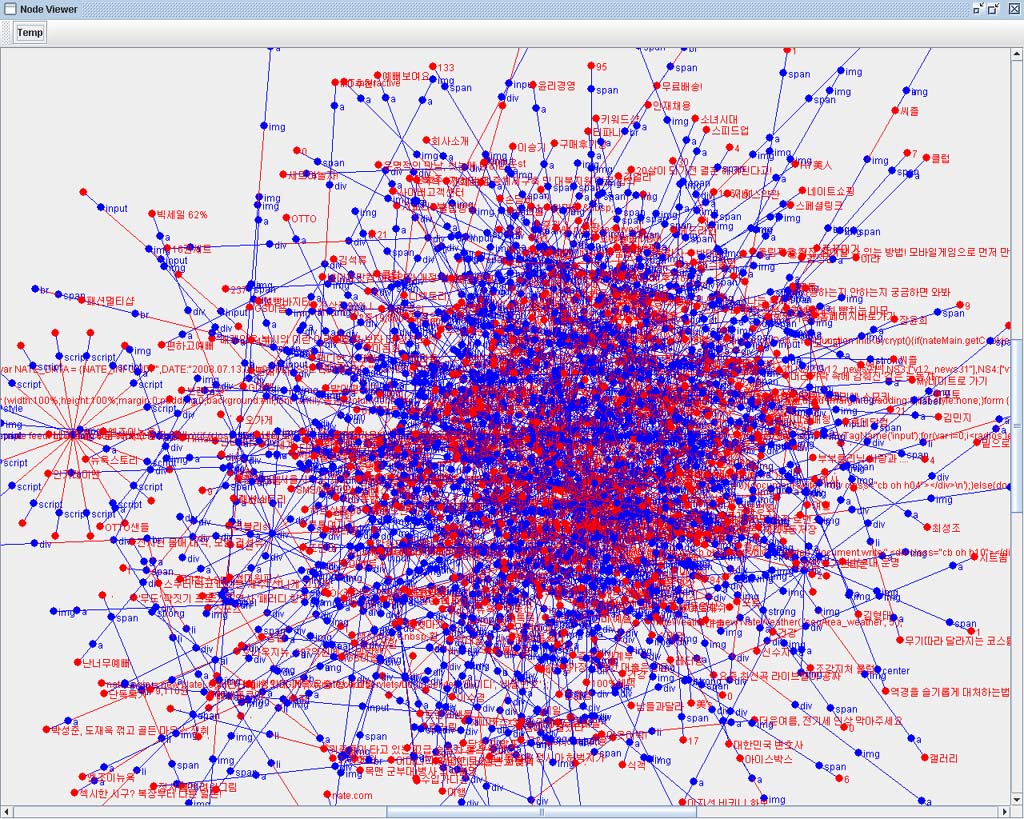
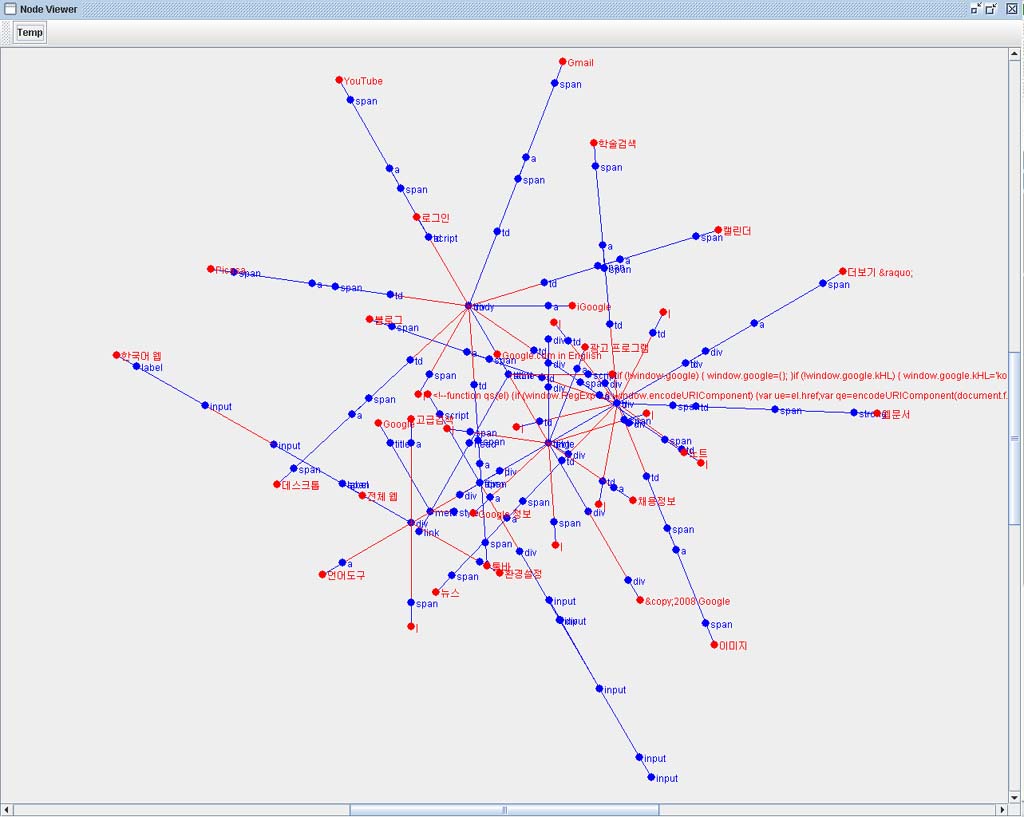
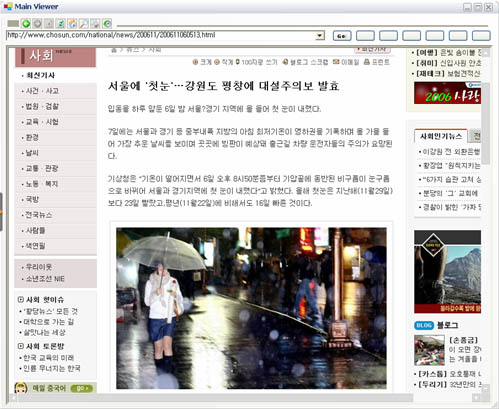
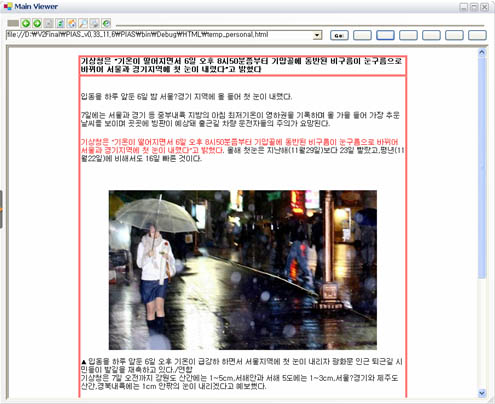
Crawler에 의해 추출된 웹페이지를 적절히 Indexing 하기 위해서는 해당 문서에 본문영역을 추출(Filtering)하는 것은 검색의 정확도에 있어 매우 중요한 부분이다.

관련된 연구논문에 따르면 본문과 상관없는 네비게이션, 광고, 페이지 템플릿 등 본문의 내용과 관련없는 부분이 전체 Html 구성 Text에서 40% 이상을 차지한다 그런다. 물론 광고, 네비게이션, 템플릿등은 모든 페이지에서 공통적으로 등장한다면 단순하게 TFIDF과 같은 단순한 확률분포기반 Indexing 만으로도 어느정도 검색과 무관한 데이터로 가려낼 수 있기는 하지만, 이외의 여러가지 다양한 용도로 사용될 수 있고 검색의 방법론 등을 고려해 보았 을때 매우 중요한 기능 임에는 틀림없다.
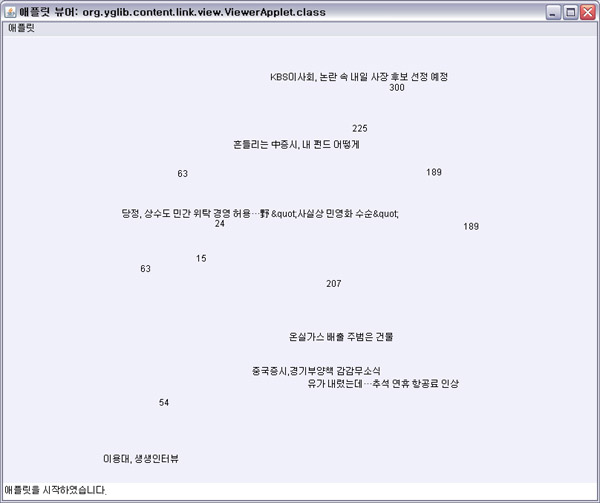
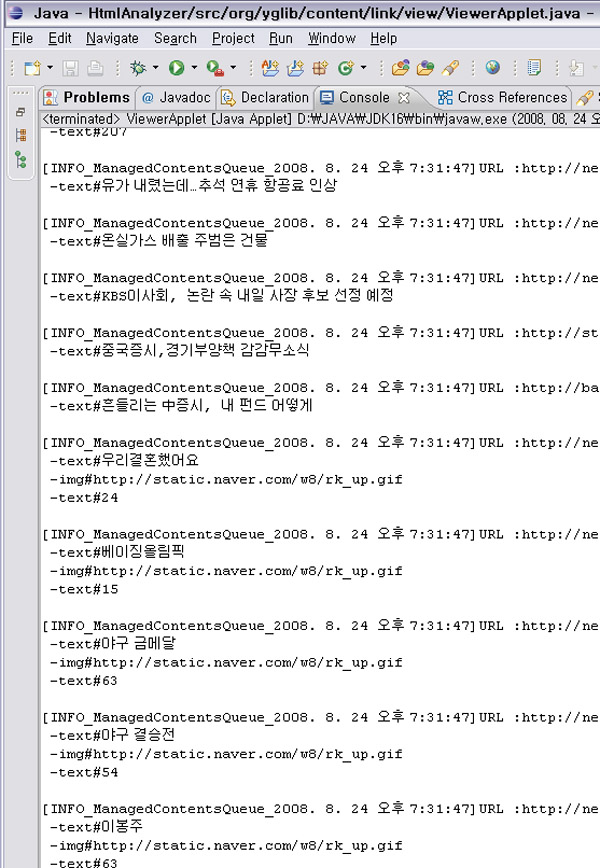
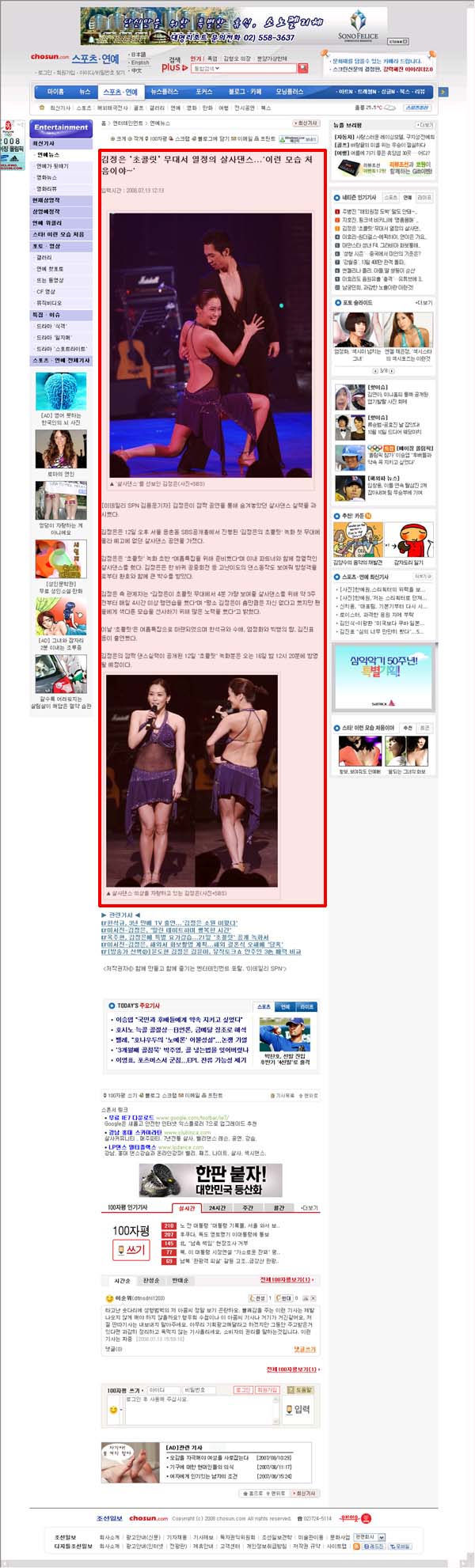
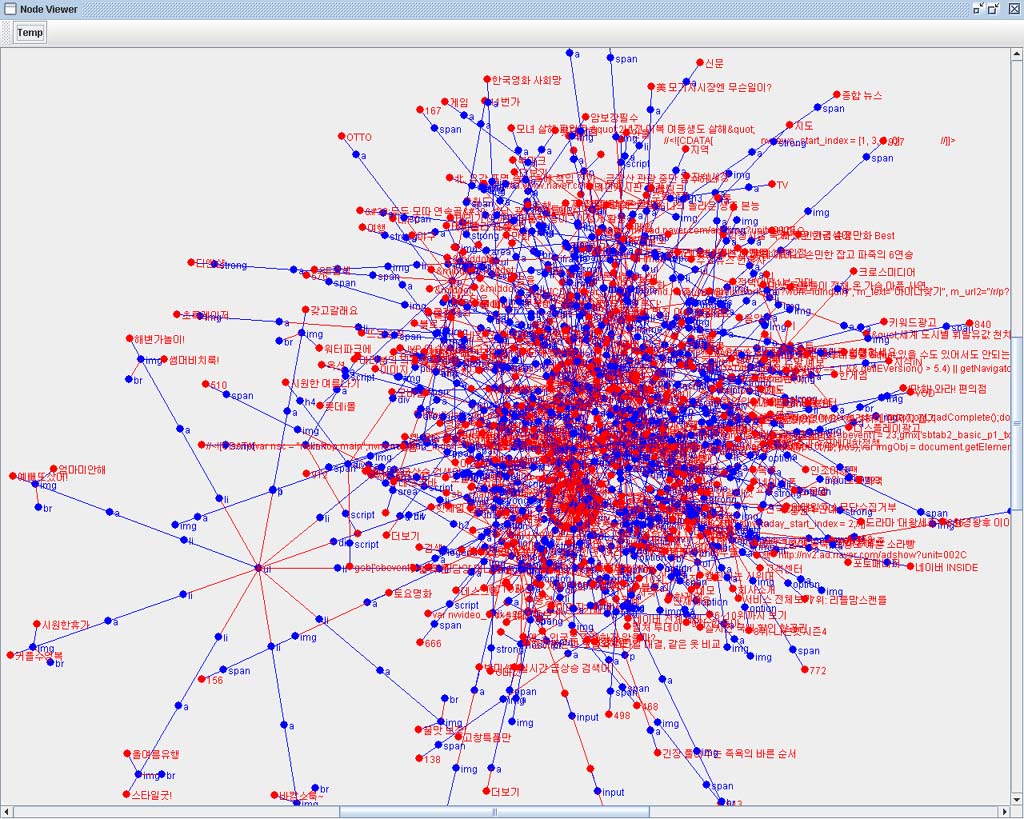
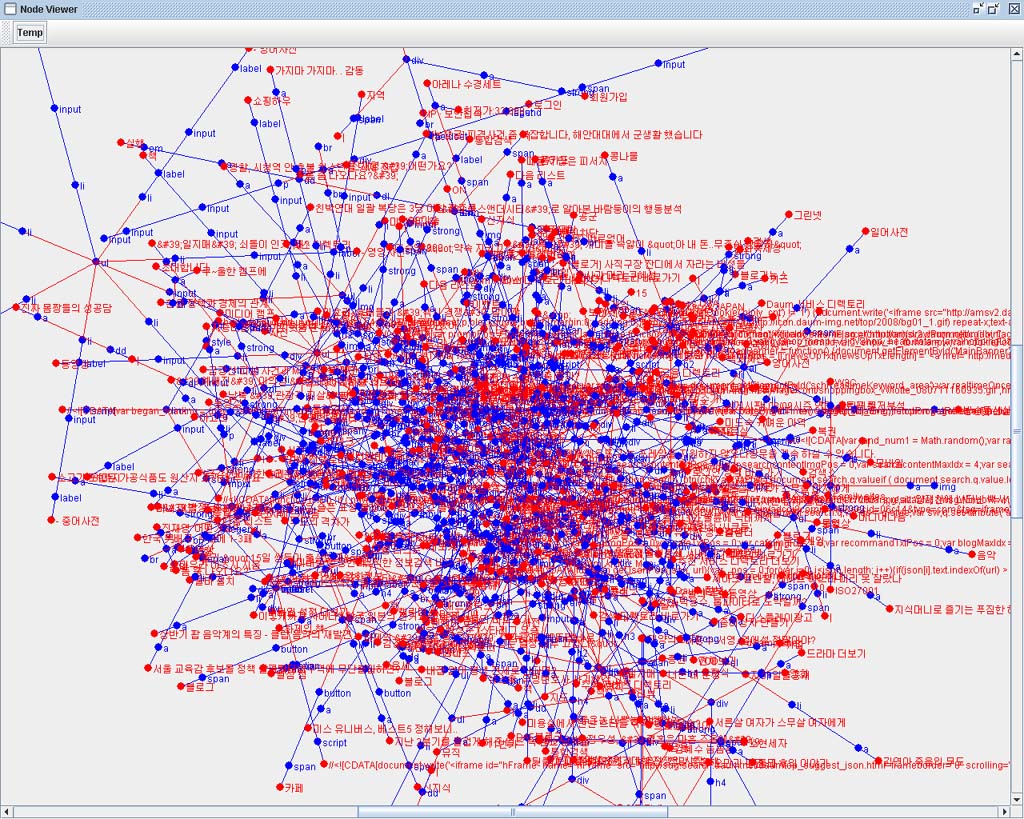
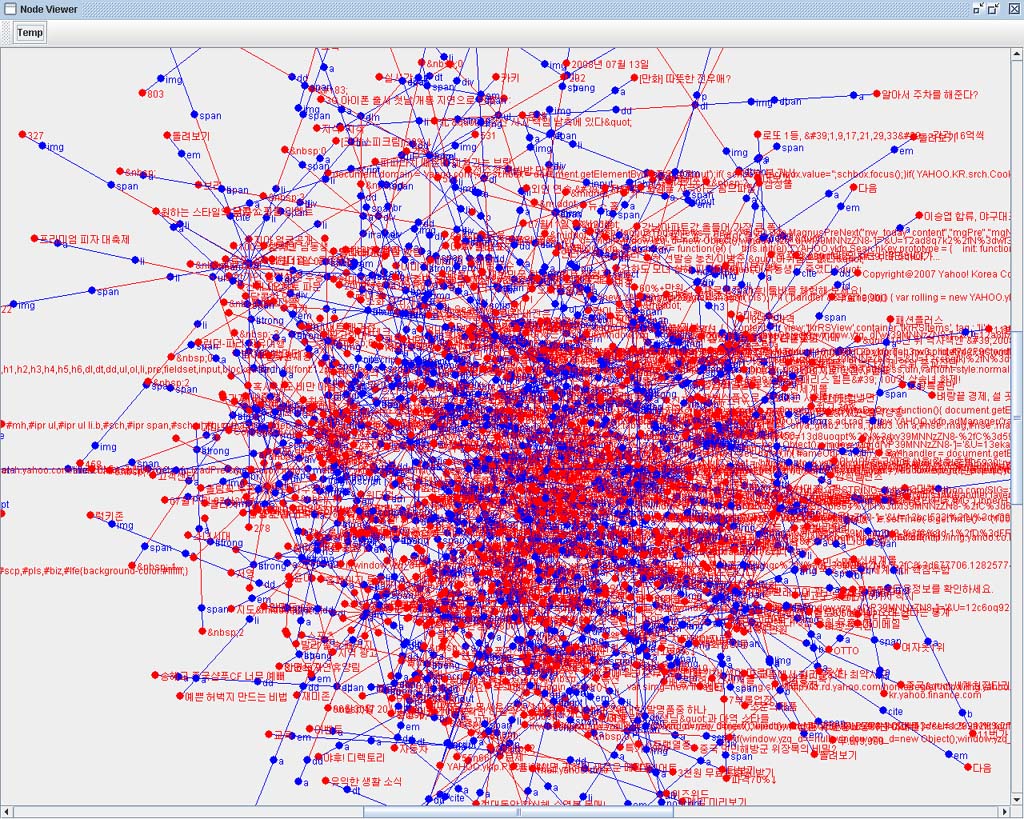
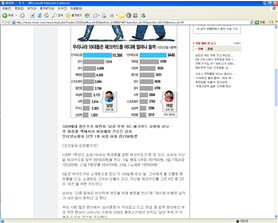
일단 아래의 신문기사의 DOM Tree를 보자.
다소 길기는 하지만 본문 영역만 자세히 보자.
본문을 추출하기 위한 가장 간단한 아이디어는 Dom Tree 를 이용하여 Link(a tag)가 설정되어 있지 않는 Text Node를 추출하는 방식이 있으나 이렇게 했을때 불필요한 텍스트를 포함하고 있을 가능성이 매우 크기때문에 2차적인 보정이 필요하다.
아래는 본문영역 추출을 위해 사용될 수 있는 간단한 방법이다.
(몇몇 논문 참조 및 개인연구를 통해 알아낸 가장 적합한 방법이라 생각한다)
|
1. Unlink Text Node를 추출하여 Dom의 Node Depth가 같은 Node의 군집을 추출한다.
(실제 구현시에는 인접노드 추출후 재병합하는 방법을 사용하였는데, 이것은 이후에 설명을 하겠다)
2. Unlink Text의 밀도를 추출하여 대량의 Text가 밀집된 영역군을 추출하고 1번에서 추출된 후보군집과의 비교를 통해 최종 추출 노드들의 공통 parent node들을 추출하고 parent의 child내의 Text Node의 조합이 본문이 된다. 여기서 추출된 parent node는 1개 이상이 된다. 덧글과 같은 비링크 데이터가 존재할 수 있기 때문이다. 그래서 다수의 후보 node 군이 추출된다.
3. 기사의 내용이 지나치게 짧다거나 기사보다 내용이 긴 덧글 등은 본문 추출의 최대의 적이다.
- 사실상 짧은 내용의 기사일 경우 정확한 추출은 불가능하다. (여러 페이지 분석을 통한 템플릿 추출 이후 가능)
- 덧글 등은 Table 태그의 구조적 Pattern 양상을 보이므로, DOM 의 구조분석을 통해서 덧글 여부를 판별 할 수 있다.
4. 가장 이상적인 방법은 언론사 사이트의 메인페이지에서 동일 level(군집)의 Link를 추출하여, 동일한 페이지 구조 템플릿을 사용하는 페이지들을 분석하여, 본문에 해당되는 DOM Tree의 Path를 추출하는 방법이다.
|
한가지 불행한 사실은 본문과 그렇지 않은 부분의 경계가 모호한 페이지도 많다는 것이다. 연구를 하다가 부딛히는 문제들중 본문의 기준을 무엇으로 볼것인가 라는 의문을 던져주는 사이트도 적지 않았다.
결국에는 패턴을 통한 기계의 자동화와 인간의 인지에 의한 영역 지정, 기계와 인간의 하이브리드된 방법이 답니다. 다시말해 추출의 대상이 되는 사이트의 XPath 형태의 본문을 포함하는 영역의 DOM 경로 추출 후 추출 값이 정확하지 않을 경우 추가 되거나 제거되어야 할 영역의 규칙을 사람에 의해 수동으로 설정이 가능하도록 하는 방법이 지금으로써는 답이다.
물론 불과 몇년전에 불가능으로 보였던 것들에 대한 구현들에 관한 내용이 최근에 계속해서 논문으로 나오고 있는 것을 보면, 수년내에 자동 본문 추출도 완전에 가까운 형태가 되지 않을까 생각된다. 아니면 사람이 좀 고생하는 거고..
김영곤 <gonni21c@gmail.com>
'Expired > Web by Agent' 카테고리의 다른 글
| 일반 웹페이지(사이트) RSS 추출기 : 사이트의 변화를 실시간으로 감지한다.. (0) | 2008.08.24 |
|---|---|
| 자바 웹크롤러(Java Web Crawler) 구현시 고려사항 들.. (8) | 2008.08.09 |
| 웹 페이지 주 내용영역 추출 및 해상도 변환 Demo.. (1) | 2008.07.13 |
| 그래프로 보는 국내 주요 포탈 시작 페이지 복잡도 분석.. (1) | 2008.07.13 |
| 웹페이지 필터링, 축약, 변환.. (3) | 2008.05.20 |