웹페이지 주내용 추출은 기술적으로 쉽지않은 기술 중에 하나다.
HTML 문법 자체도 워낙이 변칙적이고, HTML의 정규화 과정을 거쳐 DOM Tree를 생성했다 해도..
변화무쌍한 웹페이지의 특성상, 단순 Parse Tree의 탐색에 의한 알고리즘만으로는 한계가 있으며,
데이타 마이닝이나 크롤링에 의한 문서 Template 추출에 의한 방법등의 고수준의 2차 이후 보정작업이 필요하다.
하지만..
단순 DOM Tree만을 이용하여, 간단한 알고리즘만으로도 70% 정도의 정확도를 가지는 주내용 추출기의 구현은 가능하다..
[추후추가 그림]
[주내용 추출의 원리]
아래의 사진은 해당 알고리즘을 이용하여 원본 페이지에서 주내용 추출후, 주 내용에서 주제문장을 추출하는 기능의 일부분이다.
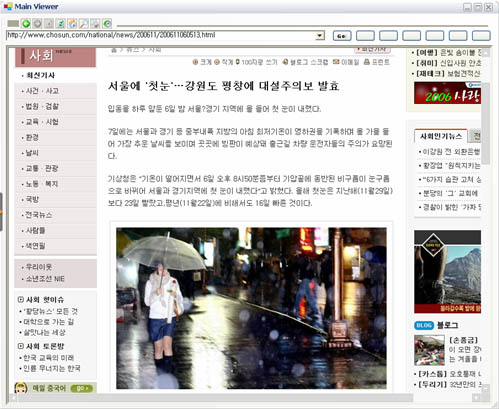
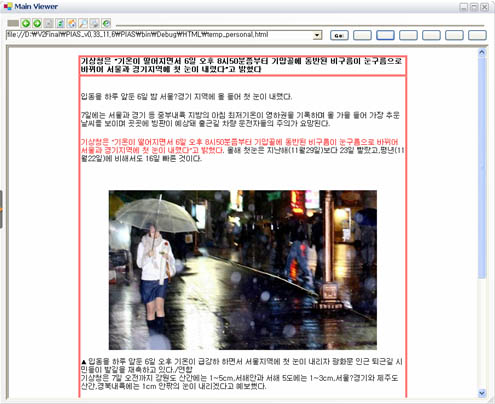
위 그림에서 처럼, 원본 페이지의 광고영역, 네비게이션 영역, 기타 정보 영역은 제거되고 문서의 핵심내용만 추출된 모습을 볼 수 있다. 붉은 색에 해당하는 문장은 추가적으로 핵심내용에서 주제문 추출 알고리즘을 적용하여 추출된 문서를 가장 잘 대표할 수 있는 문장이다.
해당 기능을 활용하면 아래와 같은 응용구현도 가능하다.
아래의 그림은 원본 문서에서 필터링을 적용, 주내용, 그림을 추출하여, 해상도가 제한적인 모바일 장비에서 해당페이지의 내용의 손실없이 볼 수 있도록 하는 페이지 제가공 기능이다.
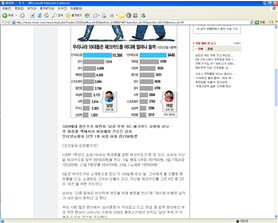
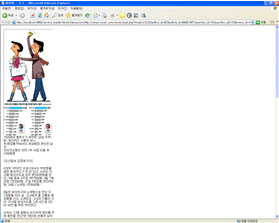
아래의 기능은 소스페이지를 제가공(주내용 추출, 해상도 변환)을 거쳐 실제로 핸드폰으로 실제 웹사이트상의 웹페이지의 내용을 보여주고 있다.
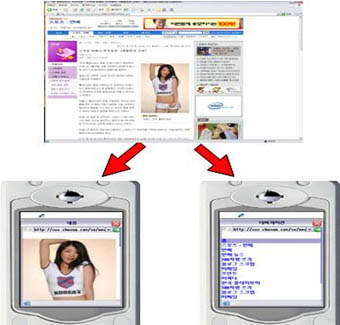

해상도가 제한적인 장비에서 별도의 좌우 스크롤 없이도 손실없는 내용을 확인 할 수 있으며, 하나의 페이지에 대해서 주내용 모드와 네비게이션 모드로 나누어 작은 화면에서 실 인터넷 사이트의 내용을 손쉽게 확인 할 수 있다.
** 위 사진은 2006년 제작된 PIAS의 실제 구현 기능임.
'Expired > Web by Agent' 카테고리의 다른 글
| 일반 웹페이지(사이트) RSS 추출기 : 사이트의 변화를 실시간으로 감지한다.. (0) | 2008.08.24 |
|---|---|
| 자바 웹크롤러(Java Web Crawler) 구현시 고려사항 들.. (8) | 2008.08.09 |
| 웹 페이지 주 내용영역 추출 및 해상도 변환 Demo.. (1) | 2008.07.13 |
| 그래프로 보는 국내 주요 포탈 시작 페이지 복잡도 분석.. (1) | 2008.07.13 |
| 개인사용자를 위한 지능형 인터넷 정보 추천 에이전트.. (2) | 2008.02.24 |