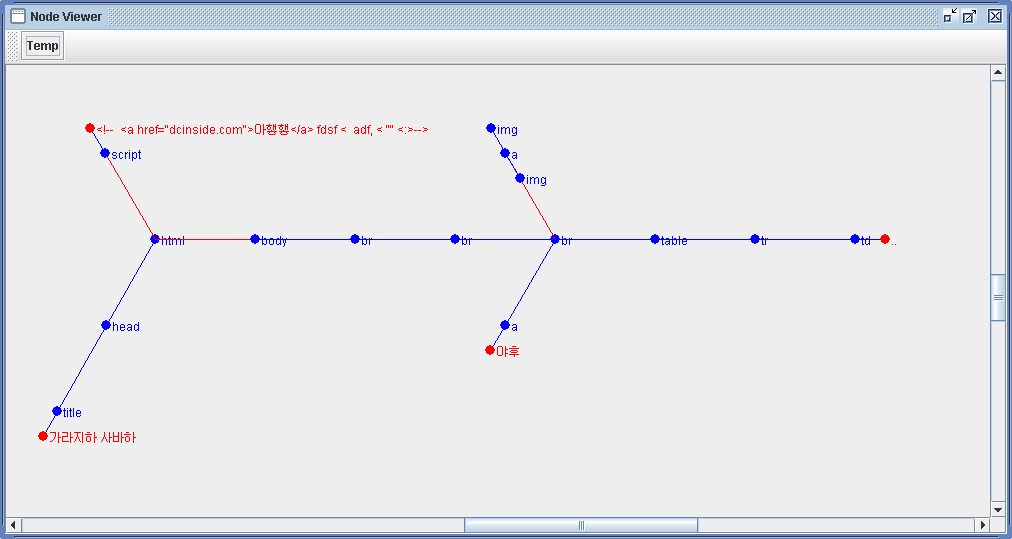
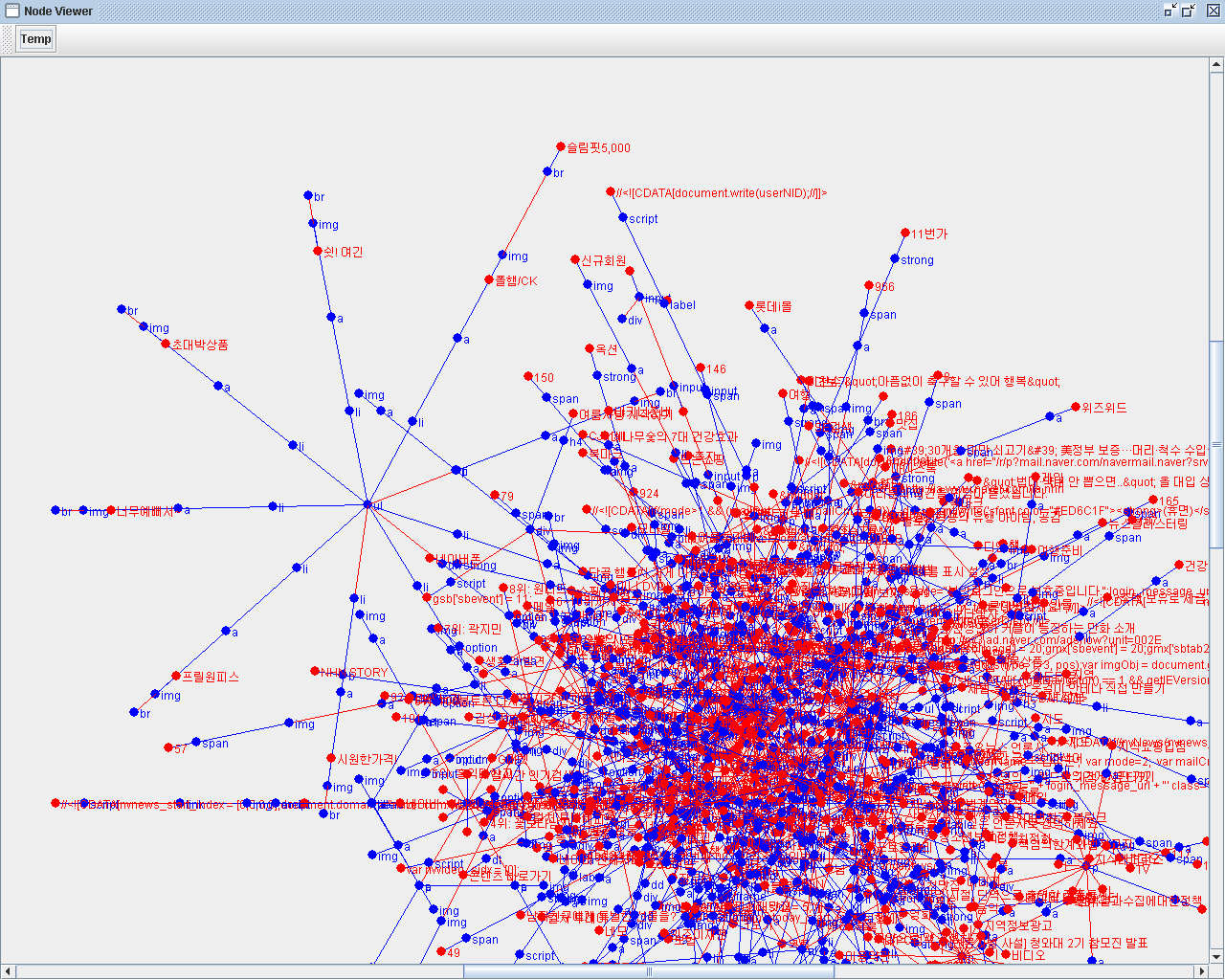
Html Parser는 검색엔진 개발에 있어 가장 기본적이면서도 문자열의 논리적 구성을 담당하는 역할을 하는 중요한 모듈이므로, 속도, 안정성, 정확성등 여러가지 섬세하게 고려해야 될 부분이 많다.
학생시절 부터 관심이 있어서 Html Parser를 어떻게 만들면 잘 만들수 있을까 참 많은 고민을 한 것 같다.
많은 세월이 흘렀음에도 아직도 해답을 찾지는 못했고, 대략적인 실패한 경험들을 토대로 개발시 고려사항들을 정리해 보고자 한다. (참고로 Version 6 정도의 Html Parser가 현재 개발중이다.)
1. HTML파서와 XML파서의 제작은 차원이 틀리다.
XML 문서와 같은 경우 Well-Formed check를 통해 Tag의 열고닫음, XML의 문법적인 유효성을 강하게 체크하지만,
HTML은 그렇지 못하다. 대표적으로 <BR> 과 같은 Tag는 </BR>과 같이 닫기Tag가 명시적으로 사용되고 있지는 않으므로,
HTML Dom Tree 생성시 계층구조 구성을 위한 별도의 처리가 필요하다.
즉, HTML은 모호성(Ambiguous)을 아직까지는 문법적으로 허용하며, 문법의 정확성을 보장할수 없는 변칙적인 언어이다.
대부분의 HTML DOM 파서는 1Pas 시 Well-Formed 조건에 맞게 XML 파서로 파싱이 가능한 형태의 문서를 생성하고,
2Pass시 Dom Tree를 생성하는 구조로 되어있다.
2. 속도와 공간사용량 타협이 필요하다.
대부분의 Parser가 아마도 최단 시간내에 Parsing을 완료하는 것을 목표로 할 것이다. 물론 정확하게 파싱해 내는 것은 말 할 것도 없다. 하지만 파서의 속도가 아무리 빠르다 할지라도 Web 상의 정보, 소스를 Network을 통해 가져오는 Html Parser의 특성상 극단적으로 속도를 빠르게 하는 것이 무의미한 작업일 수도 있다.
하지만 속도가 극단적으로 중요한 상황이라면 네트웍에서 데이터를 가져오는 동안 소스의 부분을 여러부분으로 나누어 독립적인 쓰레드의 병렬 파싱을 하도록 한는것도 가능하지만, 가장 간단하면서도 빠른 방법은 일단 데이터를 웹에서 다운받아 StringBuffer나 Char의 배열에 미리 저장해 두고 parsing하는 것이 속도 측면에서는 더 효율적이 이었다.
파싱을 위한 초기작업으로 HTML 문서에서 의미의 단위별로 텍스트의 조합, 즉 Token을 추출하는 Lexing 작업이 선행된다. 파서자체, 객체지향 프로그램 언어적 시각으로 보았을때 파싱의 대상이 되는 Source라는 커다란 객체를 문법으로 정의된 의미의 객체단위로 분리하는 작업이라 할 수 있다. 보통의 경우 Token의 Text와 Token Object가 최소한 1:1의 관계를 이루게 된다. 모든 Parser가 그러하듯 Lexing의 가장 작은 단위동작은 char, 즉 문자 하나를 소스로 부터 가져와 비교하고 그 문자 하나하나가 모여서 하나의 문자열 Token을 이루게 된다. Char단위의 문자열 연산이 상당히 많으며, String 연산 또한 많다. Token의 Size는 예측할 수 없으므로 결국 Token값의 최종결과는 정적으로 할당된 배열에 저장하게 되는데, 토큰 생성시 마다 정적배열의 생성은 극단적으로 H/W power가 약한 시스템에서는 무리가 될 수 있으며, 배열의 전체공간이 Pull인 경우 배열공간을 갱신하는(ex, StringBuffer) 자료구조를 쓸 경우 속도적인 측면에서 손해를 보게 된다.
언제나 그렇듯, 속도와 공간의 타협점을 찾아야 한다.
3. 사용언어의 추출 : UTF-8, EUC-KR
다양한 언어가 공존하고, Charset이 다양하게 존재하는 웹의 구조적 특성상, 웹에서 어떤 데이터를 취득했을때, 그 데이터가 어떠한 Charset을 사용했는지 알아내는 것이 HTML 문서 파싱의 선행 작업이라 할 수 있다. 어떠한 Charset을 사용하는지는 아래와 같은 단서를 이용해서 알 수 있다.
a. Http Protocol Header의 Charset attribute 값에서 추출
b. Html Header 내의 <meta http-equiv="Content-Type" content="text/html; charset=euc-kr">
c. <Html lang="ko"> Tag의 lang 속성
a의 경우 서버 자체적으로 제공해 주는 기능이라 최초 Lexing전 charset의 정보를 취득할 수 있으며, b, c의 경우 일단 데이터를 저장하고 pre-reading을 통해 해당정보를 추출해야 한다.(Parsing 속도 측면에서 좋은 방법은 아니며, 초기 ASCII 모드형태로 데이터를 읽으면서 해당정보가 추출된 이후 charset 형태의 맞추어 문자 읽기를 동적으로 변환하는 방법으로 가능하다)
저러한 정보를 얻을 수 없는 최악의 상황은 byte연산을 통해 현재 어떠한 type의 문자를 포함하고 있는지 별도의 연산과정이 더 필요하다.
4. 무한 루프의 가능성
앞서 언급한 바와 같이 html 언어는 모호성을 허용하며, 변칙적인 문법의 사용이나, 정확하지 않은 문법을 사용한 문서들도 상당히 많음을 항상 염두해 두어야 한다. 아마도 모든 파서가 데이터로 부터 커서나 포인터를 증가시켜 문자를 읽어들이면서 파싱이 진행되는 형태를 취하고 있을 것으로 생각된다.
커서의 진행방향이 consume만 하는, 값이 증가만 하는 단방향성만을 가진 다면 큰 문제는 없으나, 경우에 따라서는 커서의 backward가 필요한 경우가 종종 발생한다. 생각해 볼수 있는 가장 심각한 시나리오는 커서가 진행을 못해 파싱 과정에서 파서 자체의 프로세스가 무한루프에 빠지는 경우이다.
커서가 지속적으로 진행하는 단방향성을 가지는 것이 최고의 시나리오이나 그렇지 못한 문법구조를 가졌다면 무한루프의 가능성을 항상 염두해 두어야 되겠다. (불행히도 수많은 Case에 대한 Test 필요)
5. 주석처리상의 문제
위에서도 언급한 바와 같이 HTML parser의 문자처가 단방향성을 가진다면 더할 나위 없이 좋겠지만, <script>, <style> <!-- 주석 -->등 과 같은 요소로 인해 사실상 커서의 backward나 미리 읽기버퍼를 현재 문자이후에 등장하는 문자열을 검사해야 하는 경우가 발생한다.
<script>나 <style> 태그의 경우 Value값의 경우 HTML과는 다른 별개의 언어의 문법을 사용하므로 HTML Parsing 모듈이 해당 언어를 파싱할 수 있는 모듈에게 제어권을 넘기거나 혹은 </script> 나 </style>이라는 문자열이 나타날때 까지 모든 문자열을 무시해야 한다. 주석의 경우에도 마찬가지 인다.
문자 단위로 커서를 이동하면서 미리읽기를 통해 이후에 뒤따르는 문자열을 분석하는 작업이 필요하다. 속도 측면에서 상당한 마이너스가 아닐까 생각된다.
6. DOM Object의 경량화
앞서 언급한 바와 같이 Token 과 Token의 Object는 1:1 관계를 이룬다. 일반적으로 Java Application이 실행시 부하량(시간지연)에 가장 많이 영향을 주는 요소는 객체의 생성 시간이다. 객체의 생성량이 크지 않는 경우라면 시스템 성능에 미치는 영향이 미미하겠지만 대형 포털 사이트 메인페이지를 파싱하면 보통 2000개 이상의 Token이 생성된다. Token Object 객체도 똑같이 2000개 이상 생성된다는 소리이며, Tree 생성시 구조에 따라서 생성 객체수는 2배이상 증가 될 수 있다.
일반적인 프로그램에 비해 객체의 생성량이 많고, 페이지의 특성에 따라 생성되는 수를 예측할 수 없기 때문에, 일반적으로 Class 생성시 DOM을 구성하는 단위 객체는 최대한 경량화 되어야한다. C의 구조체처럼 데이터만을 포함될 수 있는 형태가 적절하며 연산이 들어간 method의 사용은 최소화 하는 것이 바람직해 보인다.
전체 디자인적으로는 Parsing 을 하는 행위모듈과 파싱후 생성되는 객체, 데이터 모듈을 Class 단위로 철저히 분리해야 한다. 또한 Parsing의 행위모듈의 경우에도 최대한 static 하거나 single object에서 실행되도록 하여, 객체의 생성 자체를 최소화 하는 것이 바람직한 방향으로 보인다.
객체의 생성이 과도하다면 Object의 메모리 영역을 clone copy를 통해 새로운 객체를 생성하는 Prototype Design Pattern을
고려해 볼 수 있으나, Prototype 패턴은 사용 class의 구조적 특성에 따라 효율이 오히려 떨어지는 경우도 있다. 객체 생성시 생성자의 구현이 복잡하다면 고려해 볼 수 있으나, 생성자의 내용이 없는 DOM의 Token 혹은 Node Object 생성시에는 시간적 효율은 거의 없거나 증가하는 양상을 보였다.
7. 문법 확장성의 고려
새로운 문법에 대한 확장성에 대한 고려도 물론 필요하다. 전체 설계시 영향을 주는 부분이고, 지나친 환장성은 속도, 공간적 효율을 저해한다. 이 부분은 현재 개발중인 YGHtmlParser Release시 별도 언급을 하겠다.
- 김영곤(gonni21c@gmail.com)
'Expired > YG Html Parser' 카테고리의 다른 글
| [Parser개발] 자바의 고성능 문자열 처리 : Rope (0) | 2009.09.12 |
|---|---|
| [자작] Java HTML Parser : YGHtml Parser V0.3.3 (5) | 2008.08.07 |
| [자작] Java HTML Parser : YGHTML Parser V0.3.1 (0) | 2008.06.21 |
| Java기반 HTML 파서(Parser) : YGHTML Parser 0.1.1 (1) | 2008.06.01 |
 invalid-file
invalid-file