본 문서에 관하여
- python을 활용하여 crawler와 고전 ml로 주가 회귀 분석 진행
- 아직 작성중
----
KODEX 코스닥150레버리지 상품의 다음날 상승, 하락, 가격을 예측하는 것을 목표로 하였다.
아래의 사이트에서 '외국인/기관 순매매 거래량' 2016년 부터의 데이터를 Crawling 하였다.

코스닥 전체의 투자자별 매매 동향 또한 동일 기간 Crawling을 하였다.

Regression 방식의 머신러닝일 적용하므로 과거의 많은 일 수의 특성의 반영이 필요하여 주요 지표에 대해서 아래와 같이 1, 2, 4주 기준으로 합산, 평균, 표준편차 Feature를 추가하였다.
def createColumns(df , name: str) :
# print(name + ' newly added ..')
df[name + '_SUM_D5'] = df[name].rolling(5).sum().shift(1)
df[name + '_AVG_D5'] = df[name].rolling(5).mean().shift(1)
df[name + '_STD_D5'] = df[name].rolling(5).std().shift(1)
df[name + '_SUM_D10'] = df[name].rolling(10).sum().shift(1)
df[name + '_AVG_D10'] = df[name].rolling(10).mean().shift(1)
df[name + '_STD_D10'] = df[name].rolling(10).std().shift(1)
df[name + '_SUM_D20'] = df[name].rolling(20).sum().shift(1)
df[name + '_AVG_D20'] = df[name].rolling(20).mean().shift(1)
df[name + '_STD_D20'] = df[name].rolling(20).std().shift(1)
feature_cols = ['VOLUME',
'COMP_BUY', 'FOR_BUY', 'FOR_CONT', 'FOR_PER', 'PERSONAL',
'FOREIGNER', 'COMPANY', 'FINANCE', 'INSURANCE', 'TOOSIN', 'BANK',
'ETC_FIN', 'GOV_FUND', 'ETC_FUND']
for col in feature_cols:
createColumns(df3, col)
다음날 종가를 예측하는게 목표이므로 output은 다음날의 종가로 설정을 하였다.
df3['END_VALUE_PRED_OUT']=df3.END_VALUE.shift(-1)
pycaret을 활용하여 모델을 생성하였다.
from pycaret.regression import *
s = setup(data = train, target='DELTA_OUT', session_id=123, normalize=True, normalize_method='zscore')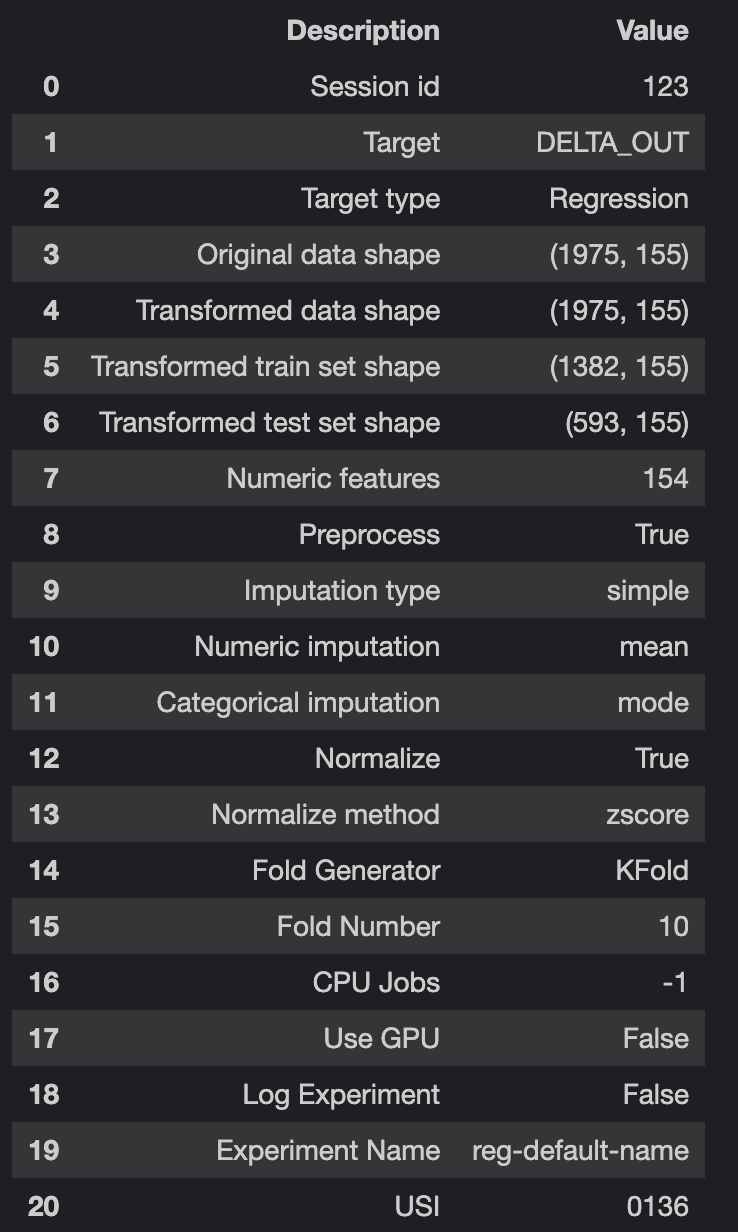
베이스라인 테스트를 진행해 보았다. 예측 정확도가 굉장히 높게 나왔다.
best = compare_models(exclude=['lar'])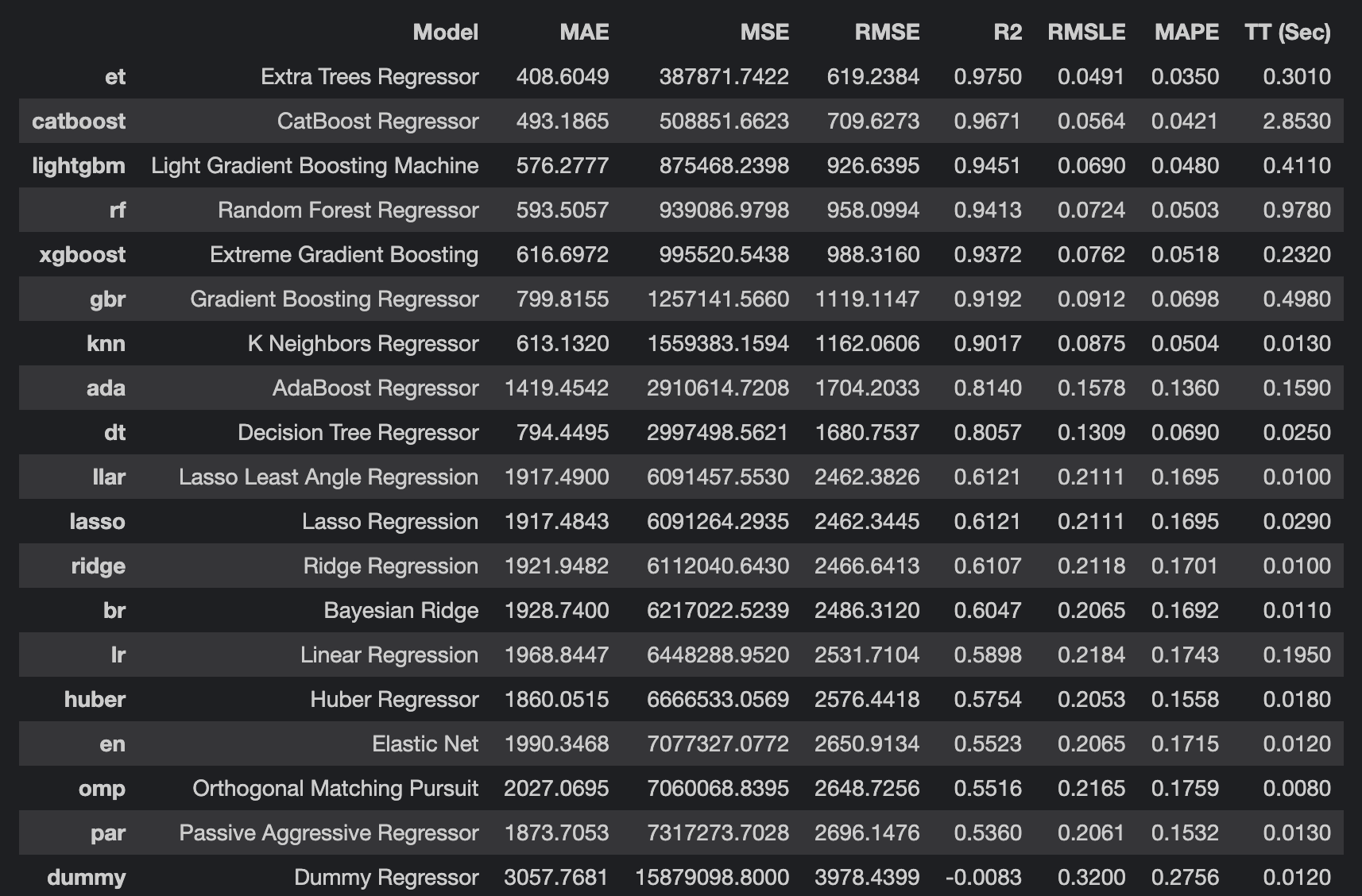
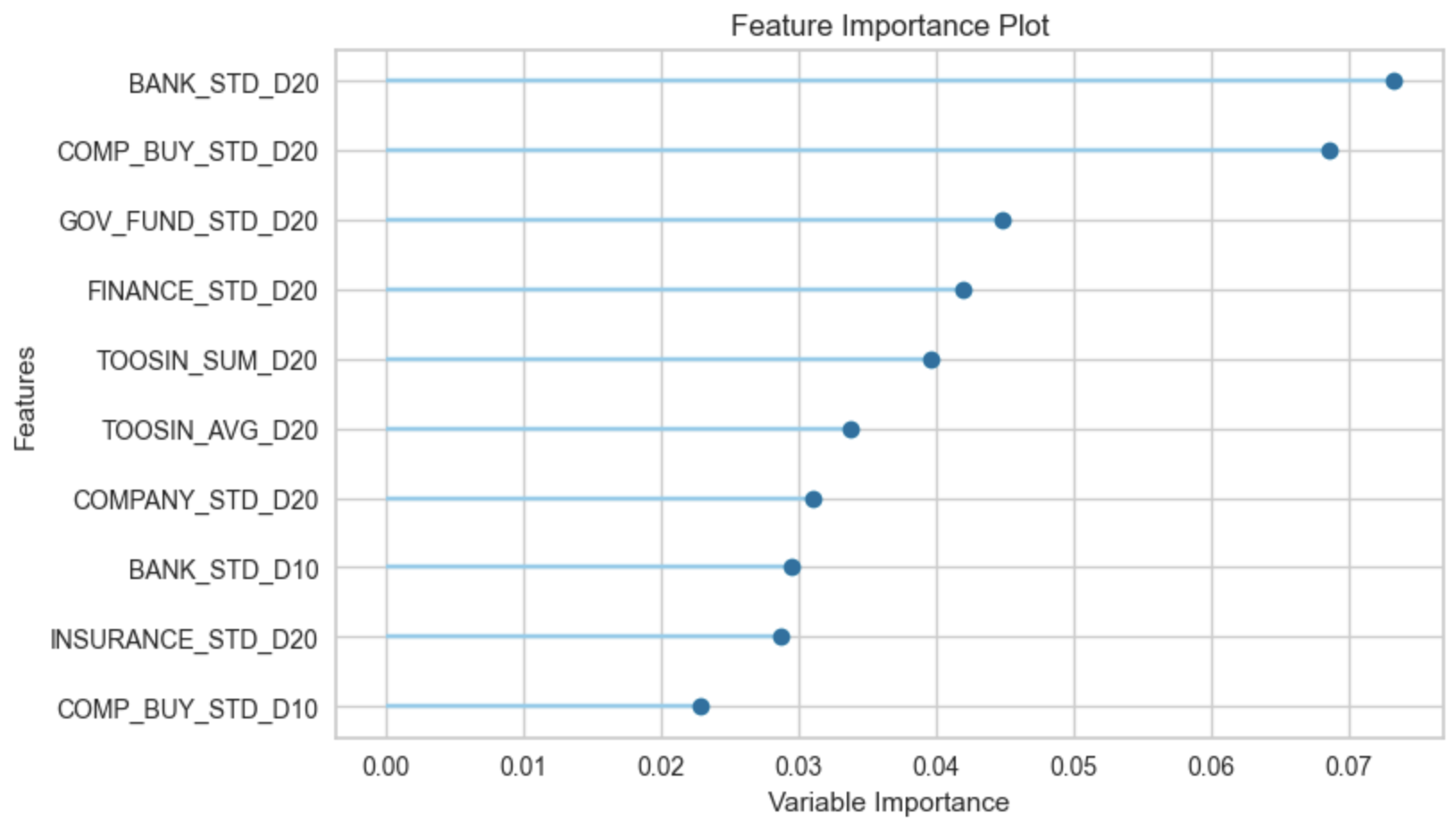
Feature Importance를 보면 대체로 한달 정도의 기간의 통계 데이터가 결과에 영향을 많이 줌을 확인할 수 있다.
SHAP value로 각 Feature별 공헌 특성을 확인해보자
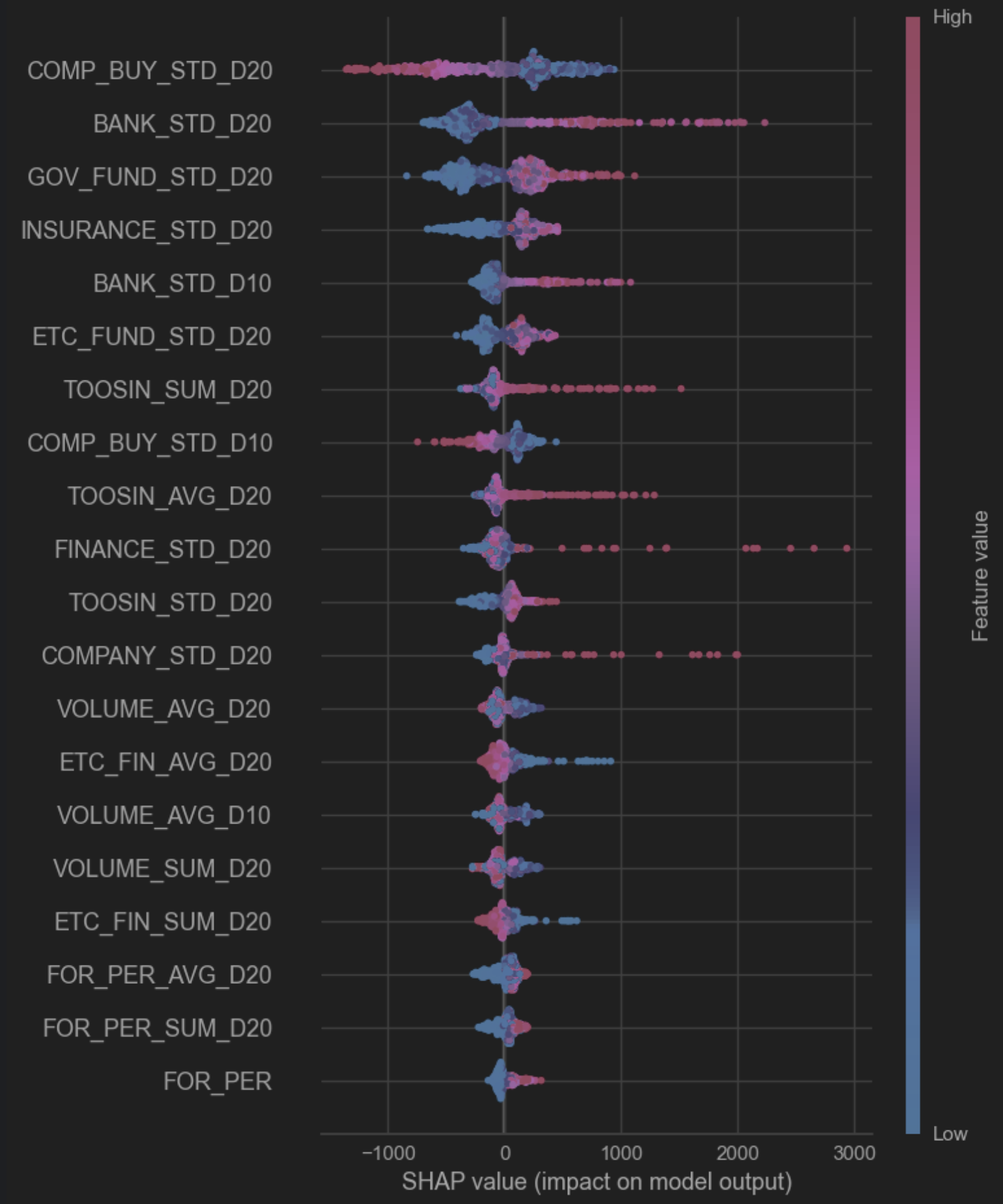
대략적인 해석은,
- COMP_BUY_STD_D20 : 기관투자자 순매수 20일치 표본표준편차, 음의 기여도를 가진다. 기관투자자 매도하는 시점은 상승으로 이어진다.
- 은행, 국민연금, 보험, 펀드 등 : 양의 기여도, 즉 주가가 상승할때 이들의 양의 매수도 증가한다 볼 수 있다.
- 투신 : 대체로 양의 기여도이나 다른 주체와는 달리 선형적이지 않다. 미리 치고 빠지는 느낌
- 외국인 : 대체로 양의 관계를 보이나 결과 영향도는 미미함.
- COMP_BUIY_STD_D10 : 20일 값과 유사하게 음의 기여도이나 기여도 자체는 20일과 비교하여 줄어드는 양상, 즉 기관 투자자들은 상승 3~4주 전에 움직인다.
LSTM은,
- 동일 데이터로 실험시 매우 저조한 예측 정확도를 출력
- Feature Engineering에 추가적인 시간 투자가 필요해 보임
- 일간 데이터이므로 딥러닝을 의미있는 정확도를 추출하기에는 데이터가 과부족로 판단됨
내일의 예측은 어떻게 할 것인가?
- 아직은 신의 영역이나 기관투자자들은 최대 한달정도 전부터 움직임, 이것을 Catch 하는 방향으로 접근이 요구됨
'Tech > DATA & AI' 카테고리의 다른 글
| 실시간 검색어를 대체하는 이슈 추적기 (0) | 2022.12.08 |
|---|---|
| SparkStream의 Source로 Mysql + Slick 연동하기 (0) | 2022.08.12 |
| 딥러닝을 활용한 댓글 감성분석 개발 및 상용화 (0) | 2021.06.28 |