역시나 YGHtml Parser 0.3.5 버전을 이용하여 주말에 구현해 보았습니다.
구현한 프로그램은 자주 바뀌는 뉴스페이지에 새롭게 추가되는 내용만을 추출하여 추출된 내용을 자체정의한 RSS 파일로 추출해주는 프로그램입니다.(웹 페이지 변경 실시간 검사)
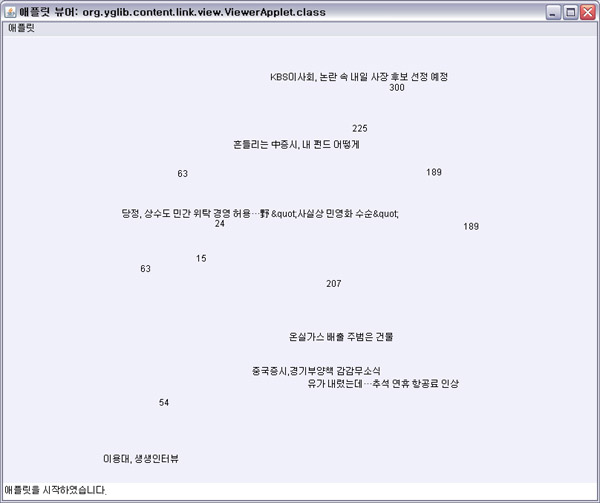
아래는 네이버(http://www.naver.com)의 메인페이지를 제가 만든 RSS 추출기를 적용하여,
자체적으로 만든 JApplet 기반의 RSS Viewer로 출력되는 화면입니다.
네이버 같은 대형포털의 경우 거의 분단위로 신규정보가 추가되기 때문에,
즉 추가되는 데이터의 양이 많으므로 거의 실시간으로 새롭게 추가되는 정보를 확인하기 위해서 아래와 같은 형태로 구현하였습니다.
아래 프로그램에서 각 문장은 오른쪽으로 스크롤됩니다. (애니메이션 화면을 캡쳐한 것입니다.)
사용자는 아래 뷰어를 단순히 보고만 있는것 만으로도 현재 새롭게 추가되는 새로운 기사를 거의 실시간으로 확인 할 수 있습니다.
웹 페이지에서 신규정보(Anchor Text)를 추출하는 작업은 쉬운 작업이 아닙니다.
아래와 같은 과정을 거쳐 신규정보를 추출 할 수 있습니다.
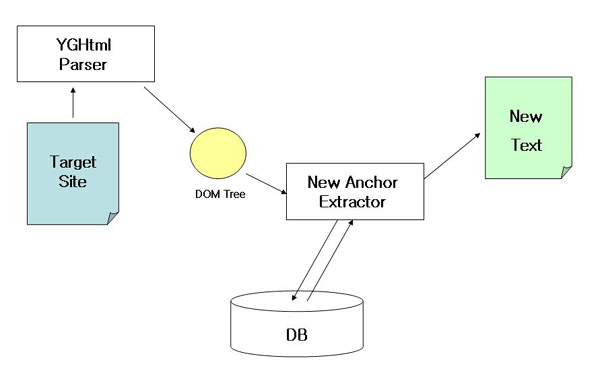
- Target Site 에 대한 Parsing을 통하여 DOM Tree를 생성합니다.
- 이전 DOM Tree와 비교를 통해 신규정보를 추출합니다.
- 신규정보를 이전에 추출된 정보가 저장된 DB를 검색하여 중복여부를 검사합니다.
- 신규 추출 요소를 DB에 저장합니다.
- 저장의 이유는 각 페이지 상 주기적 랜덤으로 표시정보로 인하여 신규정보 추출시 중복을 제거하기 위함입니다.
- 신규정보가 DB에 없을경우 최종 신규 정보로 추출됩니다.
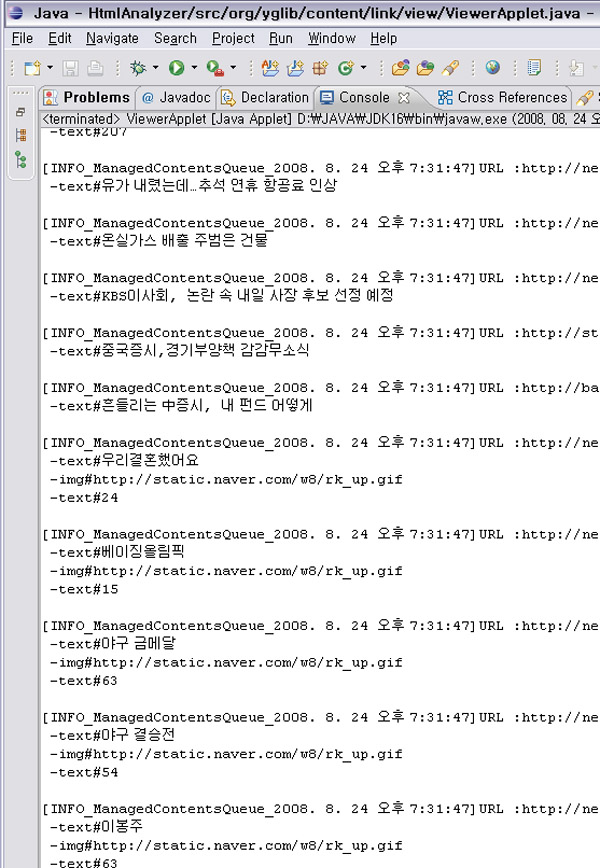
아래는 위와 같이 구현하여 실제로 Console에 출력되는 모습입니다.
잘 동작합니다만 광고를 비롯한 불필요한 정보에 대한 필터링은 필요해 보입니다.
추출 정보의 Anchor Text와 URL 정보를 토대로 RSS를 구성합니다.
RSS 구성을 위해 해당 URL 페이지의 주제문장 영역 추출이 필요한데, 웹페이지 내용요약과 주제문장 추출을 위해서는 최소한 아래의 작업을 필요로 합니다.
- 웹페이지 잡음 영역제거(필터링)
- 한국어 형태소 분석
- 문서 핵심문장 추출(시소러스, 코퍼스 적용)
위 기술에 대한 구현 방식은 본 블로그의 Web by Agent 항목의 글들을 검색해 보시길 바랍니다.
(없는 내용이 더 많을 듯..ㅋ)
내용 요약 및 핵심영역 추출에 대한 내용은 정보과학회에 관련 내용이 많으니 그 쪽 논문의 검색도 추천합니다.
이상입니다.
* Applet RSS Viewer Demo를 웹페이지에 올릴만큼 다듬는데는 2주 정도 시간이 걸릴듯 하네요.
구현한 프로그램은 자주 바뀌는 뉴스페이지에 새롭게 추가되는 내용만을 추출하여 추출된 내용을 자체정의한 RSS 파일로 추출해주는 프로그램입니다.(웹 페이지 변경 실시간 검사)
아래는 네이버(http://www.naver.com)의 메인페이지를 제가 만든 RSS 추출기를 적용하여,
자체적으로 만든 JApplet 기반의 RSS Viewer로 출력되는 화면입니다.
네이버 같은 대형포털의 경우 거의 분단위로 신규정보가 추가되기 때문에,
즉 추가되는 데이터의 양이 많으므로 거의 실시간으로 새롭게 추가되는 정보를 확인하기 위해서 아래와 같은 형태로 구현하였습니다.
아래 프로그램에서 각 문장은 오른쪽으로 스크롤됩니다. (애니메이션 화면을 캡쳐한 것입니다.)
사용자는 아래 뷰어를 단순히 보고만 있는것 만으로도 현재 새롭게 추가되는 새로운 기사를 거의 실시간으로 확인 할 수 있습니다.
웹 페이지에서 신규정보(Anchor Text)를 추출하는 작업은 쉬운 작업이 아닙니다.
아래와 같은 과정을 거쳐 신규정보를 추출 할 수 있습니다.
- Target Site 에 대한 Parsing을 통하여 DOM Tree를 생성합니다.
- 이전 DOM Tree와 비교를 통해 신규정보를 추출합니다.
- 신규정보를 이전에 추출된 정보가 저장된 DB를 검색하여 중복여부를 검사합니다.
- 신규 추출 요소를 DB에 저장합니다.
- 저장의 이유는 각 페이지 상 주기적 랜덤으로 표시정보로 인하여 신규정보 추출시 중복을 제거하기 위함입니다.
- 신규정보가 DB에 없을경우 최종 신규 정보로 추출됩니다.
아래는 위와 같이 구현하여 실제로 Console에 출력되는 모습입니다.
잘 동작합니다만 광고를 비롯한 불필요한 정보에 대한 필터링은 필요해 보입니다.
추출 정보의 Anchor Text와 URL 정보를 토대로 RSS를 구성합니다.
RSS 구성을 위해 해당 URL 페이지의 주제문장 영역 추출이 필요한데, 웹페이지 내용요약과 주제문장 추출을 위해서는 최소한 아래의 작업을 필요로 합니다.
- 웹페이지 잡음 영역제거(필터링)
- 한국어 형태소 분석
- 문서 핵심문장 추출(시소러스, 코퍼스 적용)
위 기술에 대한 구현 방식은 본 블로그의 Web by Agent 항목의 글들을 검색해 보시길 바랍니다.
(없는 내용이 더 많을 듯..ㅋ)
내용 요약 및 핵심영역 추출에 대한 내용은 정보과학회에 관련 내용이 많으니 그 쪽 논문의 검색도 추천합니다.
이상입니다.
* Applet RSS Viewer Demo를 웹페이지에 올릴만큼 다듬는데는 2주 정도 시간이 걸릴듯 하네요.
김영곤(gonni21c@gmail..)
'Expired > Web by Agent' 카테고리의 다른 글
| HTML 본문 추출(Filtering)에 대한 고찰 (2) | 2010.08.29 |
|---|---|
| 자바 웹크롤러(Java Web Crawler) 구현시 고려사항 들.. (8) | 2008.08.09 |
| 웹 페이지 주 내용영역 추출 및 해상도 변환 Demo.. (1) | 2008.07.13 |
| 그래프로 보는 국내 주요 포탈 시작 페이지 복잡도 분석.. (1) | 2008.07.13 |
| 웹페이지 필터링, 축약, 변환.. (3) | 2008.05.20 |