SpaceBar 버튼을 누르면 노드가 하나씩 추가됨..
프린스턴 대학에서 제공하는 traer라는 확장 라이브러리를 이용하여 Spring 형태의 물리적인 움직임을 처리..
'Expired > Web Art' 카테고리의 다른 글
| d3.js를 활용한 t-sne 데이터 시각화 (0) | 2017.07.21 |
|---|---|
| Java 물리 시뮬레이션 툴 (0) | 2008.11.03 |
| d3.js를 활용한 t-sne 데이터 시각화 (0) | 2017.07.21 |
|---|---|
| Java 물리 시뮬레이션 툴 (0) | 2008.11.03 |
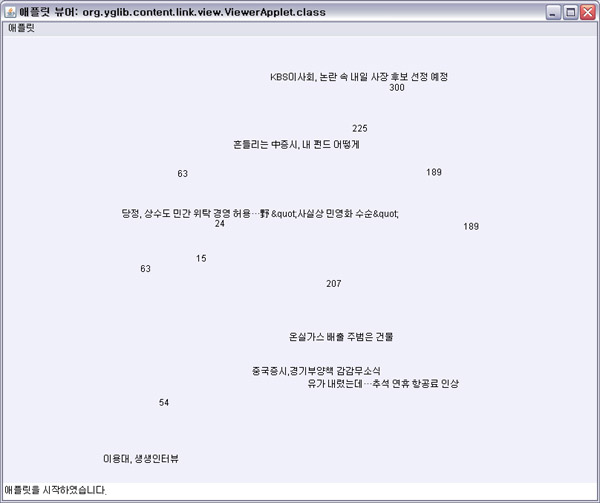
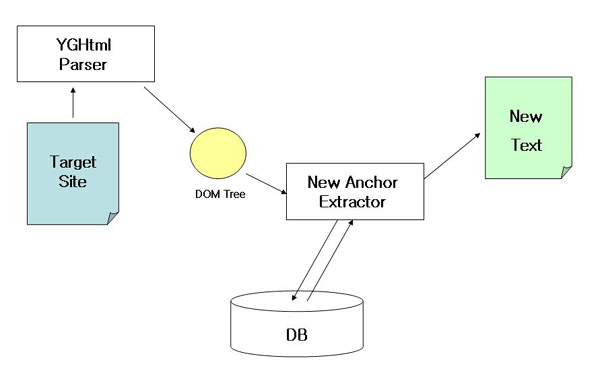
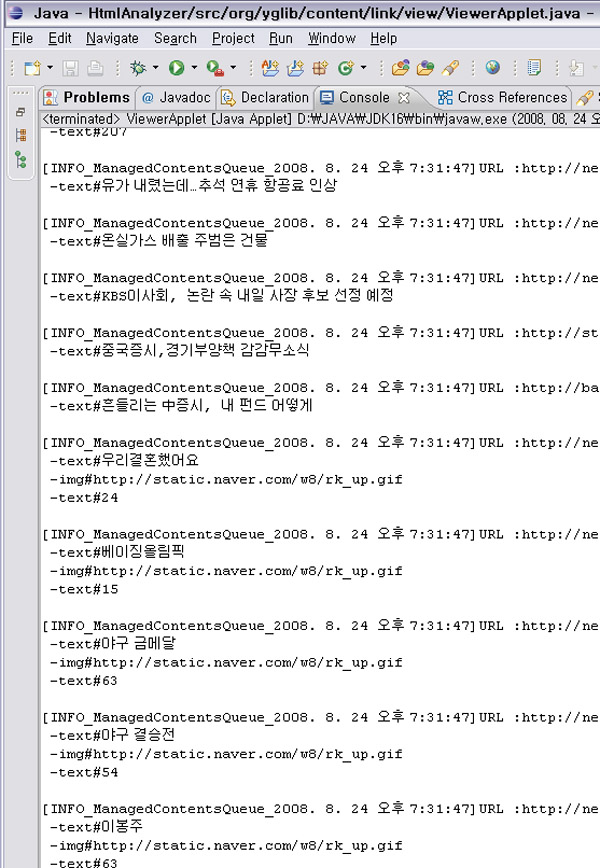
| HTML 본문 추출(Filtering)에 대한 고찰 (2) | 2010.08.29 |
|---|---|
| 자바 웹크롤러(Java Web Crawler) 구현시 고려사항 들.. (8) | 2008.08.09 |
| 웹 페이지 주 내용영역 추출 및 해상도 변환 Demo.. (1) | 2008.07.13 |
| 그래프로 보는 국내 주요 포탈 시작 페이지 복잡도 분석.. (1) | 2008.07.13 |
| 웹페이지 필터링, 축약, 변환.. (3) | 2008.05.20 |
주말을 이용하여 만들어본 웹크롤러..
일반적인 웹크롤러는 다음과 같은 과정으로 URL을 수집합니다..
- Root Site Source Download
- 해당 페이지에서 정규식을 이용하여 'http://www~' 와 같은 주소로 인식되는 문자열 추출
- 추출 주소에 대한 재귀적 반복 (깊이 우선 탐색 or 너비 우선 탐색)
위와 같은 구현은 단일 Thread로 구현시 재귀적 호출구조를 가지므로 간단하게 구현할 수 있지만..
일반적으로는 지정 Site에서 source를 download할때 network blocking time이 크기 때문에.. (CPU를 최대로 활용 못함)
보통 Crawler는 MultiThread기반으로 만들어 집니다.
아래는 위에서 설명한 크롤러와는 틀리게 Anchor Text 기반 URL 및 Anchor Text(링크문장) 추출하는 크롤러..
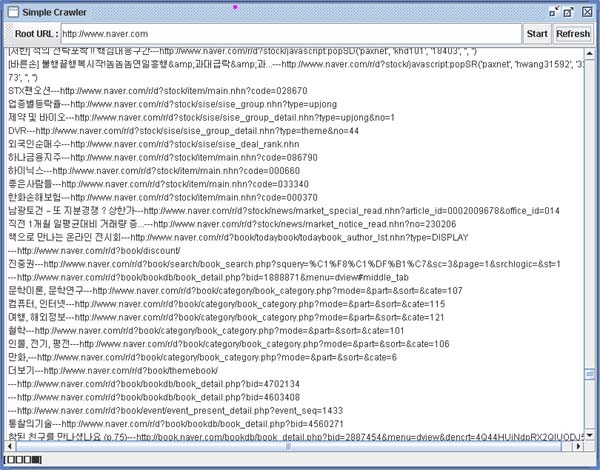
다음은 위의 크롤러를 구현하면서 생각해본 크롤러 구현시 고려사항들 입니다..
1. 최근 검색의 추세로 볼때 Crawling 된 URL을 잘 활용하기 위해서는 ..
URL을 대표하는 문자열로 볼수 있는 Anchor Text의 추출이 데이터 활용 측면에서 유용해 보입니다.
물론 이러한 추출을 위해서는 HTML lexing이 필요하므로 정규식을 사용한 URL 추출보다는 속도상 손해를 감수해야 합니다.
2. Crawling 시 최대한 데이터를 빨리 수집하기 위해서는 CPU 자원을 최대로 활용할 수 있어야 한다는 것입니다.
앞서 설명했듯이 Network 사용으로 인한 Blocking으로 단일 Thread로는 자원을 최대로 쓸 수 없습니다.
위의 Crawler는 Blocking Thread Pool을 이용하여 동시에 4개의 Thread가 URL-Anchor Data를 수집합니다..
하나의 주소에 대해서 Crawling Thread가 생성되면 Thread 객체 생성이 과다하므로 Thread Pool의 사용도 필수적이라 할 수 있습니다.
물론 Pool의 구현도 Blocking이 아닌 NonBlocking 으로 구현시 더할 나위 없겠죠..
기초적인 Thread Pool의 구현은 아래 Site를 참고하세요..
http://gyro74.zerois.net/lecture/threadpool.htm
3. Crawler의 최대 난제는 수집정보의 중복을 제거하는 것입니다.
하나의 Root에서 시작되는 크롤러는 다수의 파생 페이지를 연쇄적으로 Crawling 하므로, 유기적인 연결구조를 가지는 웹문서의 특성상 반드시 다수의 페이지에서 중복 URL이 발생 할 수 밖에 없습니다.
이러한 중복을 check 하기 위해서 위의 크롤러에서는 검색이 빠른 Hash 함수를 사용했습니다만 depth가 깊어짐에 따라 저장 자료가 급격히 늘어나 결국 heap space Exception으로 프로그램이 종료되는 현상이 발생 하였습니다.
즉, URL 중복을 고속으로 검사하기 위해서는 추출 데이터를 메모리상에 유지해야 하지만 용량의 한계가 있기때문에, 메모리의 용량과 속도와의 타협점이 필요하다는 것입니다. 물론 중복으로 데이터를 수집하고 수집데이터에 대해 2차 보정 작업을 거치는 구현으로도 이 문제를 해결 할 수 있습니다.
결론은, Crawler를 제대로 구현할려면,
NonBlocking Queue 기반의 Crawler Process Pool,
CPU 사용량 check에 의한 Pool Size의 동적 조절,
데이터 중복 검사를 위한 적절한 자료구조의 개발이 필수적으로 보입니다.
| HTML 본문 추출(Filtering)에 대한 고찰 (2) | 2010.08.29 |
|---|---|
| 일반 웹페이지(사이트) RSS 추출기 : 사이트의 변화를 실시간으로 감지한다.. (0) | 2008.08.24 |
| 웹 페이지 주 내용영역 추출 및 해상도 변환 Demo.. (1) | 2008.07.13 |
| 그래프로 보는 국내 주요 포탈 시작 페이지 복잡도 분석.. (1) | 2008.07.13 |
| 웹페이지 필터링, 축약, 변환.. (3) | 2008.05.20 |
| Java Html Parser 개발시 유의사항 정리 (0) | 2010.08.20 |
|---|---|
| [Parser개발] 자바의 고성능 문자열 처리 : Rope (0) | 2009.09.12 |
| [자작] Java HTML Parser : YGHTML Parser V0.3.1 (0) | 2008.06.21 |
| Java기반 HTML 파서(Parser) : YGHTML Parser 0.1.1 (1) | 2008.06.01 |

| 일반 웹페이지(사이트) RSS 추출기 : 사이트의 변화를 실시간으로 감지한다.. (0) | 2008.08.24 |
|---|---|
| 자바 웹크롤러(Java Web Crawler) 구현시 고려사항 들.. (8) | 2008.08.09 |
| 그래프로 보는 국내 주요 포탈 시작 페이지 복잡도 분석.. (1) | 2008.07.13 |
| 웹페이지 필터링, 축약, 변환.. (3) | 2008.05.20 |
| 개인사용자를 위한 지능형 인터넷 정보 추천 에이전트.. (2) | 2008.02.24 |
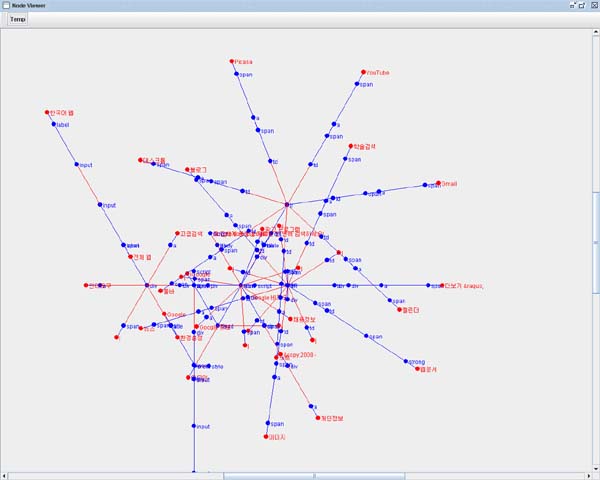
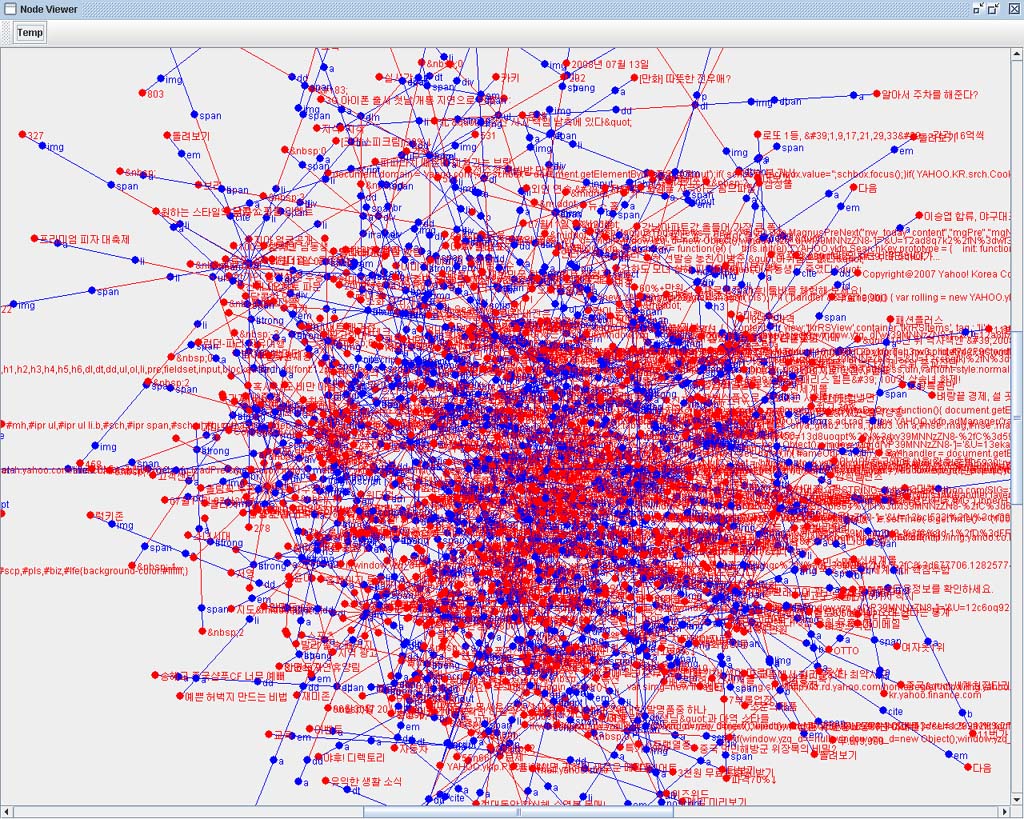
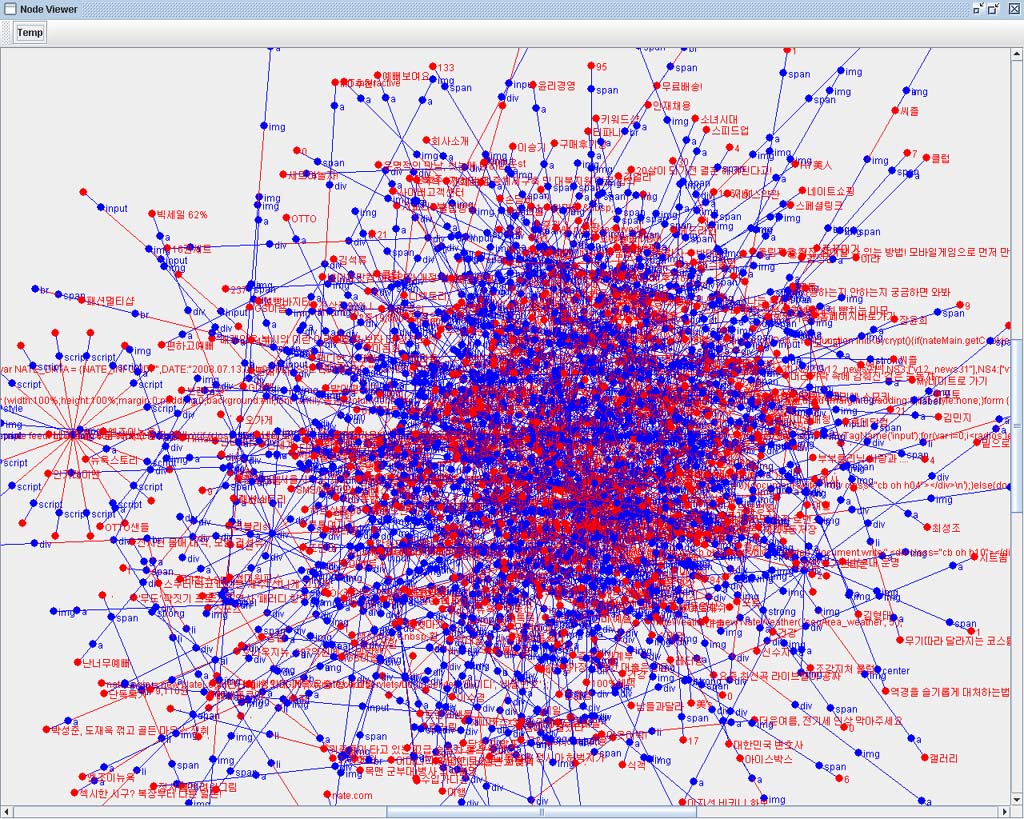
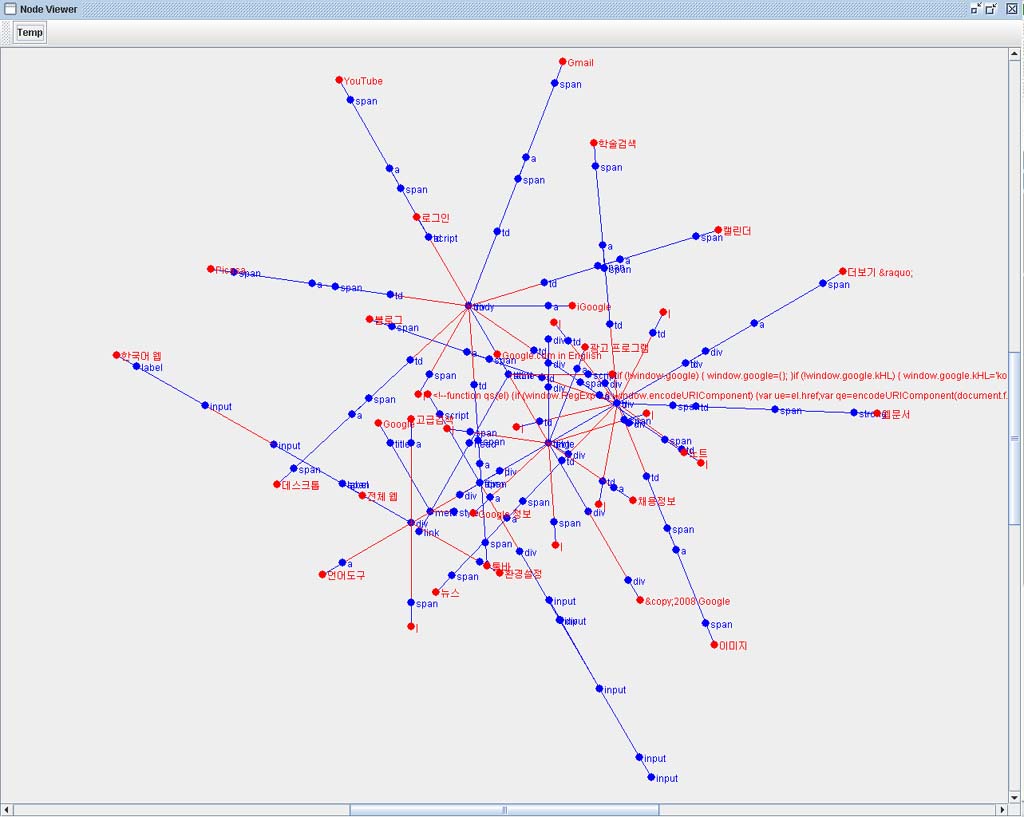
YGHtml Parser VIewer로 국내주요 포탈사이트의 시작페이지를 분석해 보았다.
국내 1위의 네이버..
처리 Token 수 : 2359
대형포탈 중에서도 가장 작은 Token수를 자랑했다.
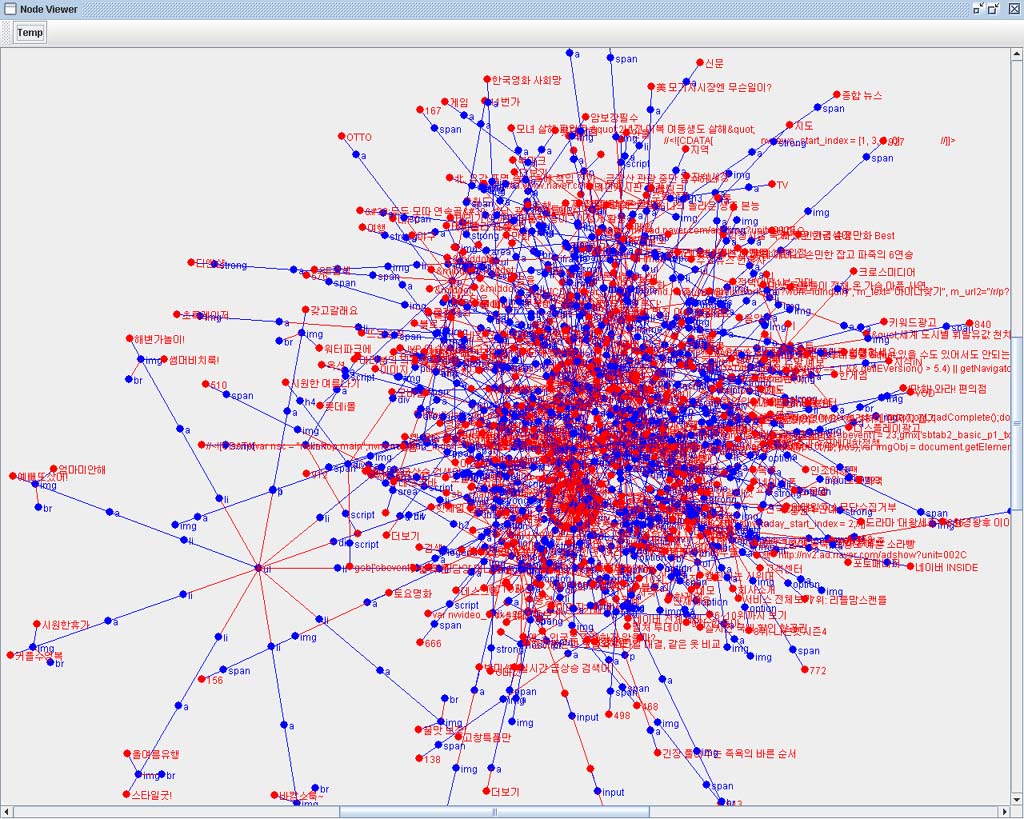
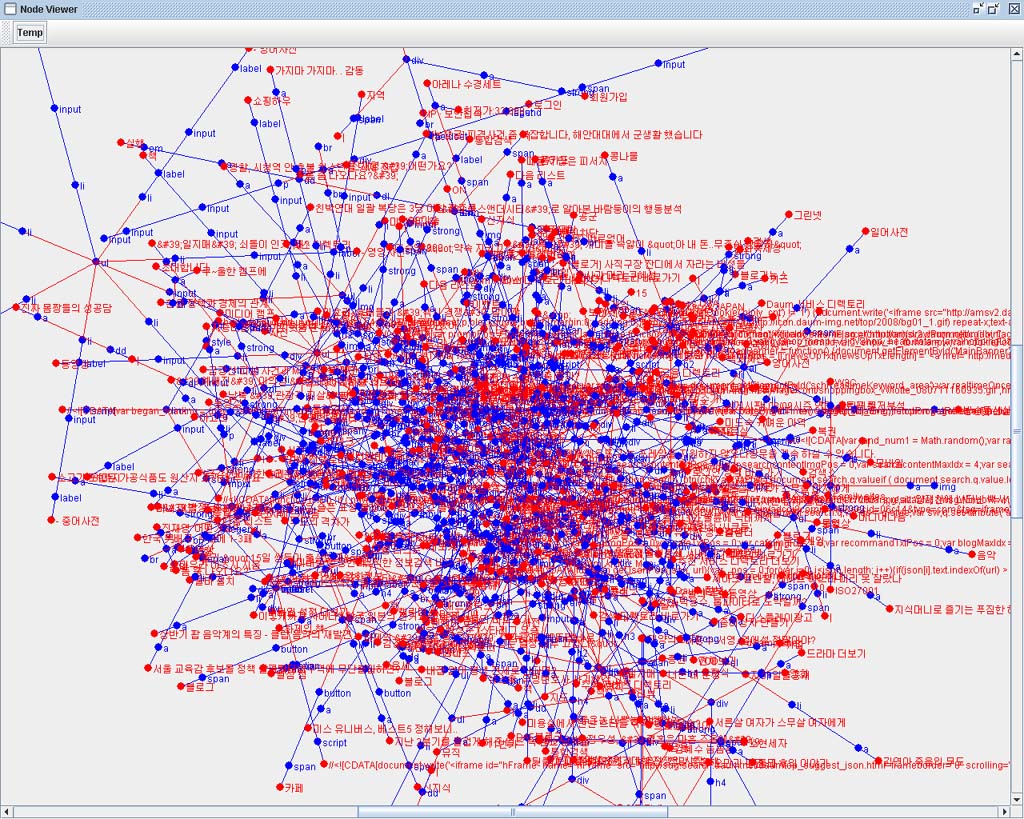
| 일반 웹페이지(사이트) RSS 추출기 : 사이트의 변화를 실시간으로 감지한다.. (0) | 2008.08.24 |
|---|---|
| 자바 웹크롤러(Java Web Crawler) 구현시 고려사항 들.. (8) | 2008.08.09 |
| 웹 페이지 주 내용영역 추출 및 해상도 변환 Demo.. (1) | 2008.07.13 |
| 웹페이지 필터링, 축약, 변환.. (3) | 2008.05.20 |
| 개인사용자를 위한 지능형 인터넷 정보 추천 에이전트.. (2) | 2008.02.24 |
 invalid-file
invalid-file