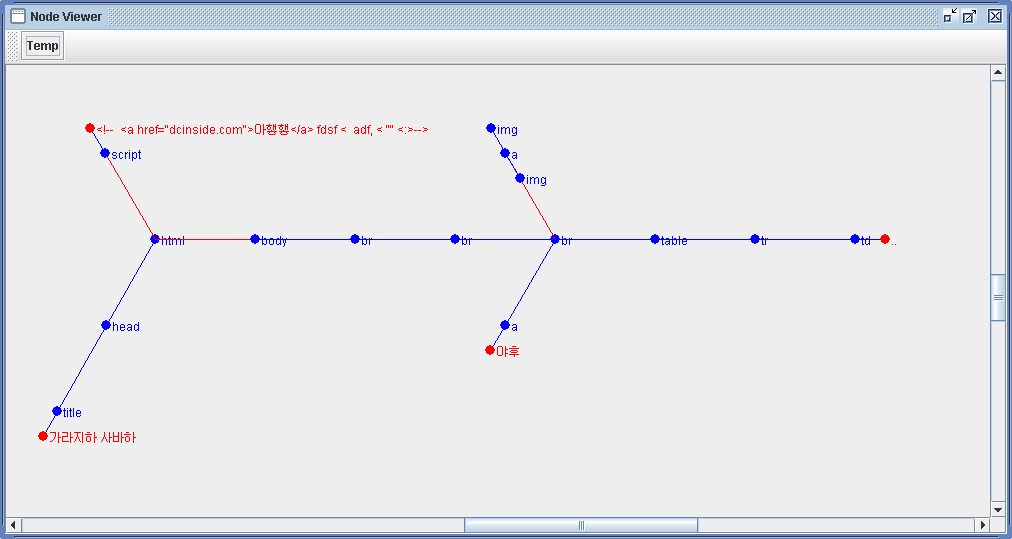
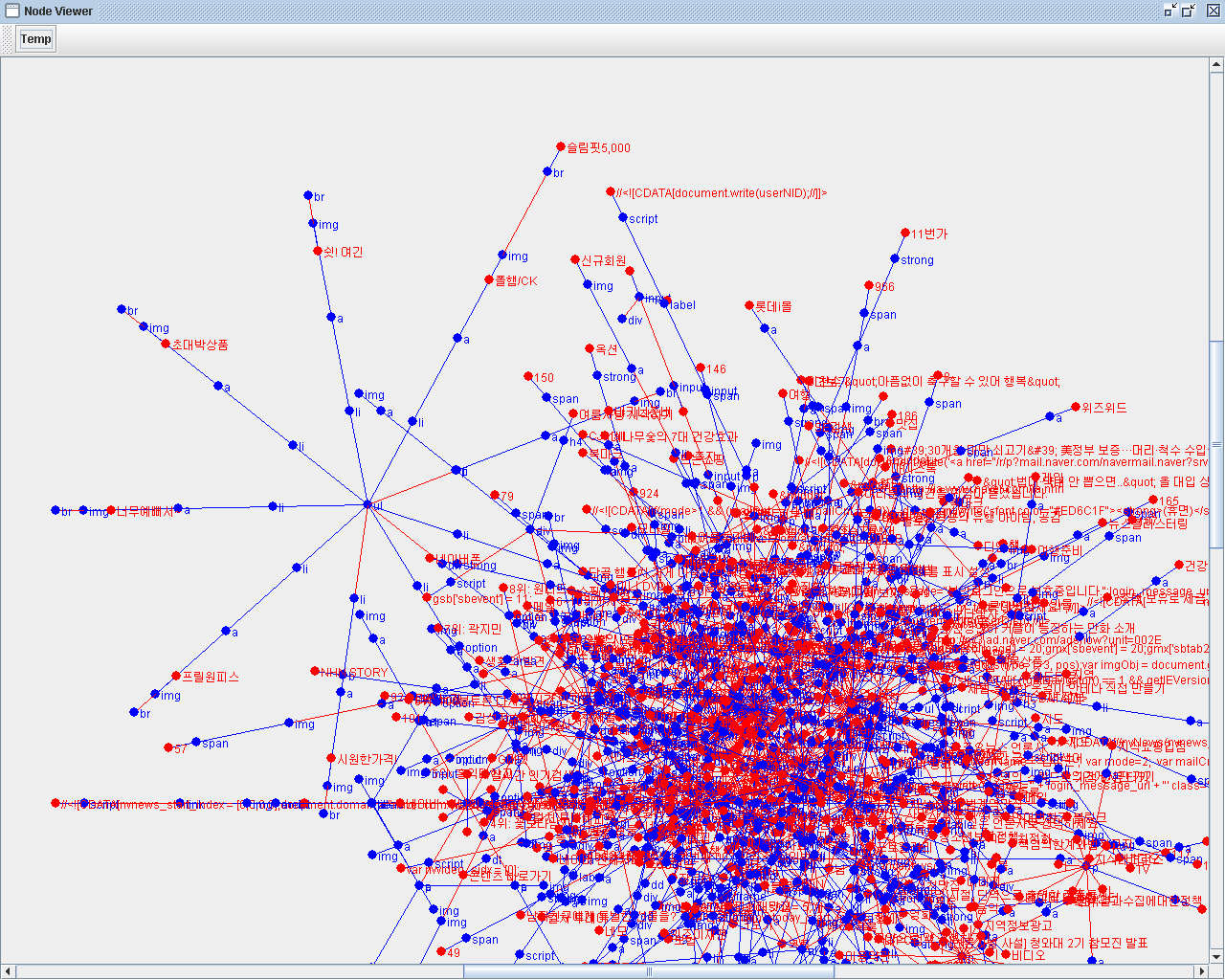
제가 그냥 개인적으로 만들어 쓰고 있는 자바 기반 Html 파서 , YGHtml Parser 0.3.3 버전입니다.
이 Parser는 최대한 가벼우면서도 정확히 Token을 추출할 수 있어야 한다는 목적으로 제작되고 있습니다..
타 공개 Parser에 비해 제공 기능은 많이 떨어지지만, 가볍고 빠르고 대부분의 공개 Parser에서 잘못된 처리를 하는 JavaScript나 Comment 부분의 Token을 비교적 정확히 추출하는데 중점을 두었습니다.
이전 버전에 비해 개선사항은 아래와 같습니다.
- String 연산을 StringBuffer로 대체, 처리속도 대폭향상
- 일부 Lexing 오류 제거
** 보고된 문제점
- Style Tag Value 처리 불가
아래는 해당 프로젝트내에 org.yglib.html.ui.NodeViewer를 실행하여 얻은 Google 첫 페이지, HTML DOM Tree Rendering 화면입니다.
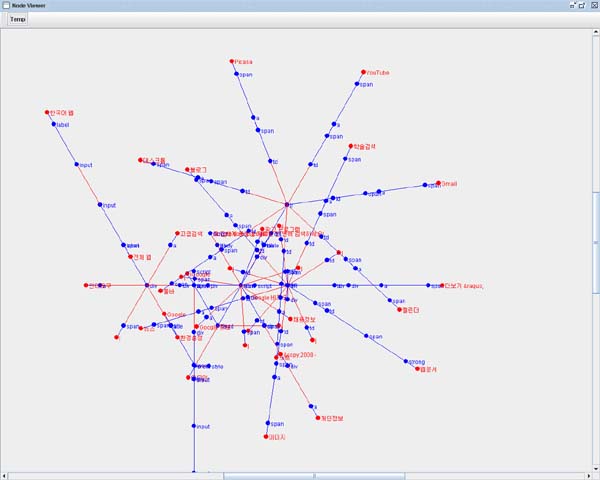
국내 대형포탈 첫화면은 대부분 정상적으로 처리하였으나 일부 페이지에서는 여전히 Parse Tree 생성시 모호성 처리상의 문제로 정상적으로 동작하지 않습니다.
사용법은 프로젝트 내의 각 파일의 main method의 코드를 참조하시면 충분하리라 생각됩니다.
프로젝트 다운로드 :
아직 최종배포를 위한 Interface는 정의되지 않았습니다. DOM 부분은 표준화된 XML 기반의 API를 참조하여 인터페이스를 구현할 예정입니다.
이번이 여기서 배포되는 마지막 버전이 될지도 모를것 같네요. 흠..
이 Parser는 최대한 가벼우면서도 정확히 Token을 추출할 수 있어야 한다는 목적으로 제작되고 있습니다..
타 공개 Parser에 비해 제공 기능은 많이 떨어지지만, 가볍고 빠르고 대부분의 공개 Parser에서 잘못된 처리를 하는 JavaScript나 Comment 부분의 Token을 비교적 정확히 추출하는데 중점을 두었습니다.
이전 버전에 비해 개선사항은 아래와 같습니다.
- String 연산을 StringBuffer로 대체, 처리속도 대폭향상
- 일부 Lexing 오류 제거
** 보고된 문제점
- Style Tag Value 처리 불가
아래는 해당 프로젝트내에 org.yglib.html.ui.NodeViewer를 실행하여 얻은 Google 첫 페이지, HTML DOM Tree Rendering 화면입니다.
국내 대형포탈 첫화면은 대부분 정상적으로 처리하였으나 일부 페이지에서는 여전히 Parse Tree 생성시 모호성 처리상의 문제로 정상적으로 동작하지 않습니다.
사용법은 프로젝트 내의 각 파일의 main method의 코드를 참조하시면 충분하리라 생각됩니다.
프로젝트 다운로드 :
 invalid-file
invalid-file아직 최종배포를 위한 Interface는 정의되지 않았습니다. DOM 부분은 표준화된 XML 기반의 API를 참조하여 인터페이스를 구현할 예정입니다.
이번이 여기서 배포되는 마지막 버전이 될지도 모를것 같네요. 흠..
'Expired > YG Html Parser' 카테고리의 다른 글
| Java Html Parser 개발시 유의사항 정리 (0) | 2010.08.20 |
|---|---|
| [Parser개발] 자바의 고성능 문자열 처리 : Rope (0) | 2009.09.12 |
| [자작] Java HTML Parser : YGHTML Parser V0.3.1 (0) | 2008.06.21 |
| Java기반 HTML 파서(Parser) : YGHTML Parser 0.1.1 (1) | 2008.06.01 |